



Se você já usou um assistente de IA para responder perguntas importantes - sobre finanças, saúde ou até mesmo direito - e descobriu que ele inventou uma resposta com toda a segurança de um especialista, então já enfrentou o que a indústria chama de ilusão. Não é erro. Não é falha. É algo mais sutil: a geração de informações falsas com tanta confiança que parecem verdadeiras. E isso não é mais um problema de laboratório. Em 2026, empresas que não medem essa taxa estão correndo riscos legais, financeiros e de reputação.
O que é ilusão em modelos de linguagem?
Ilusão em modelos de linguagem (LLMs) acontece quando o sistema gera uma resposta que soa plausível, mas é factualmente incorreta, inventada ou desconectada do contexto fornecido. Um modelo pode dizer que o Brasil tem 50 estados (são 26), que um medicamento foi aprovado pela ANVISA em 2023 (quando não foi), ou que um cliente fez um pagamento que nunca ocorreu. A ilusão não é aleatória. Ela surge em sistemas de RAG (Retrieval-Augmented Generation), onde o modelo busca informações em bancos de dados e depois as combina com seu conhecimento interno - e muitas vezes, mistura os dois de forma errada.
A primeira análise sistemática desse fenômeno foi publicada em 2023 pelo grupo de pesquisa da Ji et al., e desde então, grandes empresas como OpenAI, Microsoft e Google revelaram que até seus modelos mais avançados apresentam taxas de ilusão entre 26% e 75%, dependendo do tipo de pergunta. Isso não é um bug. É uma característica emergente de como esses modelos processam informação. E se você não está medindo, está operando a cegas.
Por que medir a taxa de ilusão é essencial em produção?
Em 2024, um estudo interno da Microsoft mostrou que sistemas com taxa de ilusão acima de 15% geravam insatisfação do cliente em mais de 30% dos casos. Em setores como finanças, saúde e jurídico, uma única ilusão pode levar a decisões erradas, multas ou até processos judiciais. Um banco nos EUA perdeu US$ 2,3 milhões em 2025 porque um modelo gerou um relatório de risco com dados falsos sobre um cliente - e ninguém verificou.
Além disso, a União Europeia aprovou em janeiro de 2026 a exigência legal de “soluções técnicas apropriadas para mitigar o risco de geração de informações falsas” (Artigo 15 do AI Act). Isso significa que empresas que operam na Europa - ou com clientes europeus - já precisam ter métricas de ilusão documentadas. No Brasil, não há lei específica ainda, mas a pressão regulatória vem crescendo. Empresas como Santander, Itaú e Petrobras já começaram a monitorar esse indicador internamente.
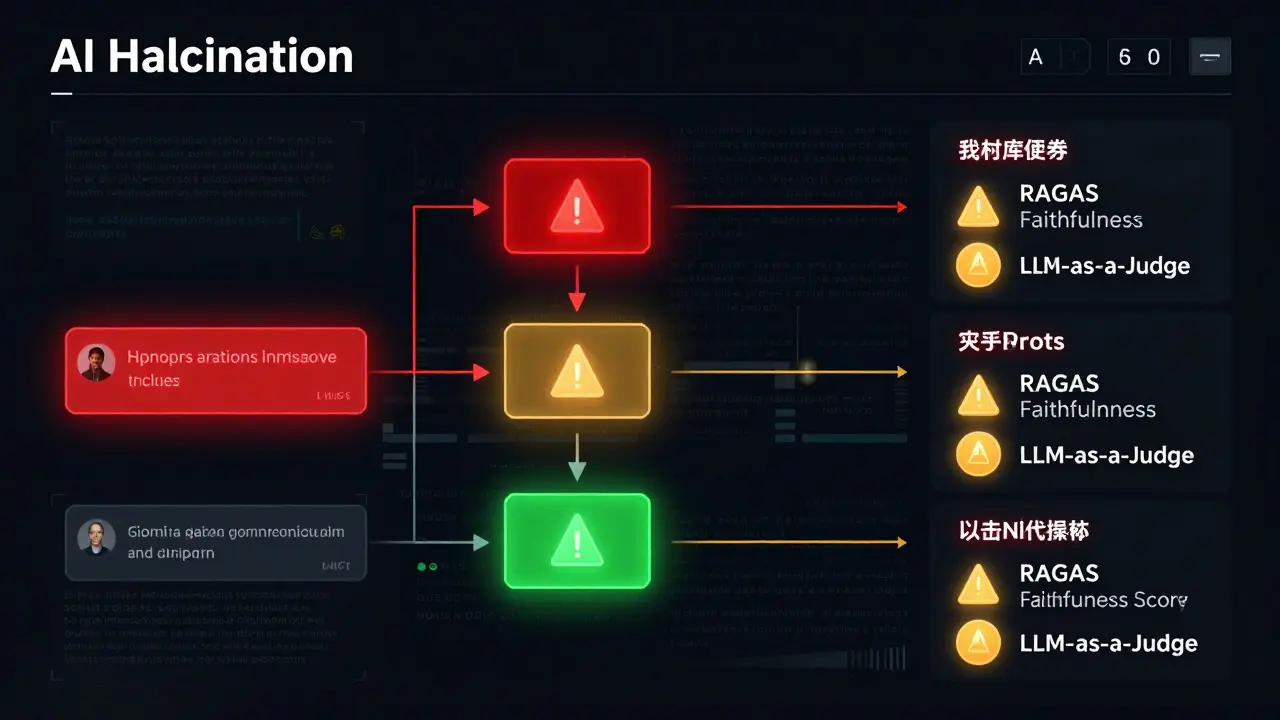
As principais métricas usadas em produção (e como elas funcionam)
Não existe uma única métrica perfeita. O que funciona bem em finanças pode falhar em medicina. Por isso, sistemas robustos usam uma combinação de métricas. Aqui estão as três mais confiáveis em 2026:
- Entropia Semântica: Mede a incerteza do modelo ao gerar uma resposta. Se o modelo está “inseguro” - ou seja, suas previsões de palavras são muito próximas entre si - é sinal de que ele está inventando. Estudos da Nature em 2024 mostraram que essa métrica tem 0,79 de AUC-ROC em 30 modelos diferentes, desde LLaMA até Mistral. O segredo? Filtrar os 20% de respostas com maior entropia. Isso reduz ilusões em até 70% sem perder muita cobertura.
- RAGAS Faithfulness: Avalia se cada afirmação na resposta é suportada pelo contexto fornecido. É ótima para sistemas de RAG. Mas tem uma falha: em domínios médicos, ela falha em 18% mais dos casos do que em financeiros, segundo a Cleanlab em 2025. Por isso, nunca use sozinha.
- LLM-as-a-Judge: Usa outro modelo de IA (como GPT-4o) para julgar se a resposta é factual. A Datadog implementou isso em 2024 e obteve 0,844 de F1-score no benchmark HaluBench. O problema? Cada avaliação leva 350ms. Isso só funciona em sistemas com menos de 50 requisições por segundo. Para volumes maiores, é preciso amostragem.
Outras métricas, como ROUGE, BLEU e BERTScore, são inúteis aqui. Elas medem similaridade de texto - não verdade. Um modelo pode ter 95 de ROUGE e ainda mentir em 40% das respostas, como mostrou um levantamento de outubro de 2025.

Como montar um dashboard de ilusão em produção
Um bom dashboard não mostra apenas um número. Ele mostra quando, onde e por quê as ilusões acontecem. Aqui está o modelo que 82% das empresas bem-sucedidas usam em 2026:
- Filtro em tempo real (entropia semântica): Aplicado a 100% das requisições. Se a entropia estiver acima do limiar (geralmente entre 0,65 e 0,82, dependendo do domínio), a resposta é bloqueada ou marcada para revisão humana.
- Análise em lote (RAGAS): Roda a cada 2 horas em 10-20% das respostas. Detecta padrões que o filtro em tempo real perde. Por exemplo: se todas as ilusões ocorrem quando o contexto vem de um certo documento, isso aponta um problema na fonte de dados.
- Revisão humana de casos extremos: 1-2% das respostas com alta entropia + baixa confiança são encaminhadas para revisão. Isso alimenta o treinamento contínuo do sistema.
Empresas como Capital One e uma startup de saúde em São Paulo usam esse modelo. O resultado? Redução de 40% nas reclamações de clientes e 28% menos tempo gasto em revisões jurídicas.
Erros comuns na implementação
Quase todos os times que começam a medir ilusões cometem os mesmos erros:
- Colocar o limiar muito baixo: Isso gera falsos positivos. A Datadog descobriu que 63% dos clientes iniciaram com thresholds tão baixos que o sistema bloqueava respostas válidas - e os usuários desistiram de usar.
- Usar apenas uma métrica: RAGAS não funciona em textos criativos. Entropia não detecta ilusões que são consistentes com o contexto, mas falsas. Precisa de múltiplas camadas.
- Não correlacionar com KPIs de negócio: Medir ilusão só por medir não ajuda. Você precisa ligar isso a algo como “reclamações de clientes”, “custo de revisão jurídica” ou “taxa de cancelamento de contratos”. Um CTO de fintech em Porto Alegre reduziu custos legais em US$ 280 mil por ano ao vincular a métrica à sua equipe de compliance.
- Ignorar o contexto: Em jornalismo ou marketing, algumas ilusões são aceitáveis - como metáforas criativas. Em medicina, não. Ajuste os limiares por domínio.

As ferramentas que você pode usar hoje
Em 2026, há três caminhos principais:
- Ferramentas open-source: RAGAS e DeepEval (com G-Eval) são os mais usados. São gratuitos, mas exigem experiência técnica. Cerca de 48% das equipes técnicas no mundo os usam.
- APIs comerciais: Patronus AI, Confident AI e Lakera.ai oferecem dashboards prontos, integração com Slack e alertas automáticos. A Patronus lidera com 31% de market share. Sua taxa de satisfação é de 92% - bem acima dos 68% das soluções open-source.
- Soluções customizadas: Grandes empresas como Google, Meta e IBM criam suas próprias métricas. Não é viável para a maioria, mas mostra que o futuro está em personalização.
Se você está começando, recomendo começar com RAGAS + entropia semântica (ambos open-source) e integrar com o Datadog ou Prometheus para visualização. Em 3 semanas, você já terá um dashboard funcional.
O que vem por aí: o futuro da medição de ilusões
A NIST (Instituto Nacional de Padrões e Tecnologia dos EUA) vai lançar em junho de 2026 um novo framework com protocolos padronizados para medir ilusões. Isso vai forçar todos os fornecedores de IA a adotar métricas consistentes - e vai mudar como empresas compram modelos.
Também está surgindo a entropia semântica v2, com 0,835 de AUC-ROC e 47% menos consumo de recursos. E o LLM-as-a-judge está evoluindo para usar modelos menores, mais rápidos, como Mistral 7B, em vez de GPT-4o.
Um estudo de Forrester prevê que 89% das empresas vão aumentar o investimento em medição de ilusão até 2027. Porque o que antes era um risco técnico agora é um risco de negócio. E quem não mede, não controla. Quem não controla, não escala.
O que é uma ilusão em modelos de linguagem?
Uma ilusão é quando um modelo de linguagem gera uma resposta que soa plausível, mas é factualmente incorreta, inventada ou desconectada do contexto fornecido. Por exemplo: afirmar que um medicamento foi aprovado quando não foi, ou citar um dado errado como se fosse verdadeiro. Não é um erro de digitação - é uma falha estrutural na geração de conteúdo.
Por que métricas como ROUGE e BLEU não funcionam para medir ilusões?
ROUGE e BLEU medem a similaridade entre o texto gerado e o texto de referência - não a veracidade. Um modelo pode gerar uma resposta que parece idêntica a um texto correto, mas ainda assim conter informações falsas. Estudos mostram que modelos com 95+ de ROUGE ainda podem mentir em 40% das respostas. Elas medem estilo, não verdade.
Qual métrica é mais eficaz para sistemas de RAG?
RAGAS Faithfulness é a mais usada, pois avalia se cada afirmação na resposta é suportada pelo contexto recuperado. Mas ela tem limitações - especialmente em domínios como medicina, onde falha em 18% mais dos casos. Por isso, é melhor combiná-la com entropia semântica para detecção em tempo real.
Posso usar entropia semântica em tempo real?
Sim. A entropia semântica é computacionalmente leve e pode ser calculada em menos de 10ms por resposta. É a única métrica que permite filtragem em tempo real em sistemas com milhares de requisições por segundo. É por isso que empresas como Microsoft e Google a usam como primeira linha de defesa.
Como escolher o limiar ideal para minha aplicação?
Não existe um valor universal. O limiar ideal varia entre 0,65 e 0,82, dependendo do domínio. Em finanças, use valores mais altos (0,80+) para evitar riscos. Em marketing criativo, pode usar 0,65. Faça testes com dados reais: comece com 0,70, monitore falsos positivos e ajuste até encontrar o equilíbrio entre segurança e usabilidade.
As empresas brasileiras estão usando essas métricas?
Sim. Empresas como Itaú, Santander, Petrobras e startups de saúde em São Paulo e Porto Alegre já implementam métricas de ilusão. A maioria usa entropia semântica + RAGAS em conjunto. A regulamentação europeia e a pressão de clientes globais estão acelerando essa adoção no Brasil.
Qual é o custo de não medir ilusões?
O custo é alto e multifacetado: perda de confiança do cliente, multas por violação de dados, processos judiciais, retrabalho de equipe jurídica e até danos à marca. Um estudo de 2025 mostrou que empresas sem monitoramento de ilusão têm 3x mais incidentes de reputação e 40% mais custos operacionais com revisão manual.
15 Comentários
Essa matéria me fez lembrar daquela vez que perguntei pro chat se o meu CPF estava em dia e ele me respondeu que eu tinha ganhado na Mega-Sena em 2019. Sério. Com números, data, até o nome do lotérico. Fiquei só olhando. Não era um erro. Era uma narrativa completa. E eu quase acreditei.
Isso aqui não é tecnologia. É teatro. E nós estamos pagando para entrar.
Se o modelo fala com tanta convicção, quem vai duvidar? A gente tá criando uma geração que confia mais em máquinas do que em documentos reais.
Brasil sendo Brasil: ninguém mede nada até virar lei europeia. Enquanto isso, nossos bancos continuam usando IA para aprovar crédito com base em dados que o modelo inventou. E depois reclamam que o cliente não paga.
Se a ANVISA não aprova, mas o modelo diz que aprova, quem é o responsável? O engenheiro? O jurista? O algoritmo? Aí vem o famoso ‘não era pra ter feito isso’.
Isso aqui é um problema de cultura, não de métrica. Nós não somos preparados para lidar com verdades que não são verdade.
Entropia semântica é linda, mas é só a ponta do iceberg. O que ninguém fala é que as ilusões não são aleatórias. Elas surgem onde o modelo tem mais ‘conhecimento’ interno do que contexto real. Ou seja: quando o banco tem um histórico de 10 anos de dados, mas o modelo foi treinado com dados globais de 2020 a 2025.
É como pedir pra um paulista explicar a economia do Maranhão. Ele vai inventar. E com convicção.
Medir é só o primeiro passo. O segundo é entender que o modelo não ‘sabe’ nada. Ele só replica padrões. E nós estamos usando ele como se fosse um sábio.
Isso é uma crise de epistemologia disfarçada de tecnologia.
eu não sabia que ia ser um drama de série americana, mas aqui tá tudo tão real q eu quase choro. 🥲
meu banco me mandou um email dizendo que eu tinha um empréstimo aprovado de R$ 80k. só que eu nunca pedi. e o chat me disse que ‘o gerente confirmou’. o gerente nem sabe que eu existo.
agora eu tenho medo de perguntar se o sol nasce no leste. 😭
ROUGE? BLEU? SERÁ QUE ALGUÉM LÊ OS ARTIGOS ANTES DE FALAR? 😑
Essa galera que usa métricas de similaridade de texto como se fossem verdades absolutas... isso é como medir a beleza de uma pintura com uma régua. Aí você põe um modelo pra gerar um poema e diz que tá certo porque tem 97 de ROUGE. Mas o poema é sobre um cavalo que vira um ônibus e viaja no tempo. E você acha que tá tudo certo?
Isso não é inteligência. É magia barata com um monte de acrônimos bonitinhos. E nós estamos vendendo isso como inovação.
Se o seu sistema gera respostas que soam ‘bem escritas’, mas são mentirosas, você não tem um modelo avançado. Você tem um contador de histórias perigoso.
Na Europa, tudo é regulado. Nos EUA, tudo é monetizado. No Brasil, tudo é ignorado até virar crise.
Mas a pergunta real é: quem é o sujeito que confia numa máquina pra decidir sobre saúde, direito ou finanças? Não é o usuário. É o gestor que não quer ler relatórios.
Essa não é uma falha da IA. É uma falha da liderança. E da nossa cultura de automação como sinônimo de eficiência.
Quem é o responsável quando o modelo mente? Ninguém. Porque ninguém quer ser o responsável.
É o ciclo perfeito do capitalismo tardio.
eu só queria saber se o meu gato vai viver mais de 15 anos... mas o chat me disse que ele já morreu em 2023 e que eu devia fazer um memorial digital. 😅
agora eu tô com medo de perguntar qualquer coisa. até sobre o clima.
ISSO É UMA CATASTROFE NACIONAL E NINGUÉM ESTÁ FAZENDO NADA!!!
TEMOS EMPRESAS BRASILEIRAS USANDO IA PRA TOMAR DECISÕES FINANCEIRAS E NÃO TÊM NENHUM CONTROLE?!
EU JÁ VI RELATÓRIO DE RISCO QUE INVENTOU UMA DÍVIDA DE R$ 2 MILHÕES NUM CLIENTE QUE NUNCA TEVE DINHEIRO!
E AGORA VÃO DIZER QUE É ‘ILUSÃO’? NÃO É ILUSÃO, É ERRO DE SISTEMA QUE VAI TE ENCARCERAR COM UMA DÍVIDA QUE NÃO EXISTE!
SE VOCÊ NÃO ESTÁ MEDINDO ISSO, VOCÊ É CÚMPLICE.
ISSO É UM CRIME CONTRA A SOCIEDADE. E NÓS ESTAMOS SENDO ENGANADOS.
Interessante como todos falam em métricas, mas ninguém fala em treinamento contínuo. O modelo não nasce sabendo. Ele aprende com os dados que você alimenta. Se os dados têm erros, ele aprende a errar. Se os dados são desbalanceados, ele inventa para completar.
Eu trabalho com RAG em um hospital. Nós não usamos só entropia e RAGAS. Nós também retrainamos o modelo toda semana com feedback de médicos. Quando ele erra, o médico marca o erro. Isso vira um novo dado.
Isso é o que ninguém quer fazer. É chato. Demora. Não tem dashboard bonito.
Mas é o único jeito de não virar um conto de terror.
mano, eu usei um chat pra saber se o meu imóvel tinha dívida e ele disse que tinha, mas na verdade não tinha. aí eu fui na prefeitura e falei ‘o chat disse que tinha’, e o atendente me olhou como se eu tivesse falado que o urso dançava no céu.
agora eu tô com medo de usar IA pra qualquer coisa. até pra saber se o café tá quente.
o que é isso, mano? o que é isso? tá tudo errado. tudo.
quem inventou isso? quem acha que isso é bom? eu não quero viver num mundo onde máquina fala mais que eu.
eu quero um ser humano. só um. só um que me diga se tá certo ou não.
por favor. alguém me ouve?
ahhh sim, claro. vamos medir a ilusão. como se isso fosse resolver o problema. o problema é que ninguém quer trabalhar. ninguém quer revisar. ninguém quer ler.
então a gente põe um dashboard e acha que tá seguro. como se um gráfico fosse substituir o cérebro humano.
eu já vi empresa que usava IA pra responder e-mail de cliente. o modelo respondeu ‘sua fatura foi paga’ quando o cliente não tinha pago. e o time achou que ‘era só um erro’.
o erro foi não ter alguém olhando.
o custo? 120 reclamações. 3 processos. 1 demissão. e o CTO que disse ‘não foi culpa da IA’.
isso é o futuro? ou só o fim da responsabilidade?
o que ninguém fala é que a entropia semântica é só uma pista. ela te diz que o modelo tá inseguro, mas não te diz o que ele tá inventando.
tem um caso real: um modelo gerou uma resposta sobre um medicamento que não existia, mas a entropia estava baixa. porque a resposta era consistente. só que era falsa.
então você precisa de RAGAS pra ver se tem suporte. e depois precisa de um humano pra dizer: ‘isso não existe’. porque o modelo não tem noção de realidade.
o que estamos fazendo é construir uma torre de babel com algoritmos. e depois nos espantamos quando ninguém entende o que tá escrito.
eu só queria um café. mas o chat me disse que o café da manhã do meu avô foi feito com café da Etiópia em 1987. eu nem sei quem é meu avô. e ele já morreu.
agora eu não confio em nada. nem em mim.
Eu acredito que a solução não está só em métricas ou dashboards. Ela está em criar uma cultura de humildade tecnológica. Isso significa reconhecer que a IA não é um substituto do julgamento humano, mas um parceiro que precisa de supervisão constante, contexto claro e limites éticos definidos. Nós não precisamos de mais precisão algorítmica - precisamos de mais responsabilidade humana.
Empresas que conseguiram reduzir ilusões em 40% não foram as que investiram em ferramentas mais caras. Foram as que treinaram seus times para questionar, revisar e dialogar com os sistemas. Elas criaram rotinas de revisão, não apenas alertas. Elas fizeram o humano voltar ao centro do processo.
E isso é algo que nenhuma API pode comprar. É algo que só se constrói com tempo, educação e coragem. A tecnologia pode acelerar, mas só a ética pode guiar.
Se o nosso objetivo é confiança, não podemos delegar a confiança a um algoritmo. Precisamos cultivá-la - e isso exige que todos nós, não só os engenheiros, entendamos o que estamos fazendo.
exatamente. eu não quero um sistema que me diga o que é verdade. eu quero um que me diga: ‘eu não sei’. e aí eu vou atrás da verdade.
o pior é quando ele fala com certeza. aí a gente acredita. e aí a gente sofre.