




Quando você digita uma pergunta para um modelo de linguagem de grande porte (LLM), como GPT-4 ou Claude, provavelmente está compartilhando muito mais informação pessoal do que precisa. Pesquisas de outubro de 2024 mostram que usuários comuns enviam entre 69,7% e 94,3% mais dados sensíveis do que o necessário para obter uma resposta útil. Isso não é só ineficiente - é perigoso. Esses dados podem ser memorizados pelos modelos, usados para rastrear seu comportamento ou expostos em vazamentos. A solução? Minimização de dados no design de prompts.
O que é minimização de dados em prompts?
Minimização de dados significa dar ao modelo exatamente o que ele precisa - e nada mais. Não é sobre esconder informações por paranoia. É sobre eficiência e segurança. Imagine pedir ao assistente para recomendar um remédio para sua dor de cabeça. Você não precisa dizer seu nome, endereço, histórico de doenças ou nome do seu médico. Basta dizer: "Tenho dor de cabeça há dois dias, sem febre, sem náusea. O que posso tomar?". O modelo entende. Você não expõe nada desnecessário. Essa ideia não é nova. Ela vem da Lei Geral de Proteção de Dados (LGPD) e do GDPR, que exigem que empresas só coletem dados essenciais. Mas agora, com LLMs, isso virou um problema técnico. Modelos grandes, como GPT-4, conseguem inferir contextos com pouquíssimas pistas. Menos dados = menos risco. E, paradoxalmente, menos dados também podem dar respostas melhores.Três técnicas principais para minimizar dados em prompts
Há três jeitos comprovados de reduzir o que você envia ao modelo:- REDACT - Remover completamente dados sensíveis. Nome, CPF, endereço, número de cartão - tudo vai embora.
- ABSTRACT - Substituir detalhes específicos por generalizações. Em vez de "minha filha de 8 anos com asma", você escreve "criança com condição respiratória crônica".
- RETAIN - Manter tudo como está. Esse é o padrão atual. E é o mais arriscado.
Por que modelos maiores são melhores nisso?
Modelos menores, como o qwen2.5-0.5b, precisam de muito mais contexto para funcionar. Eles conseguem minimizar apenas 19,3% dos dados antes de começar a errar. Já GPT-4, com 70 bilhões+ de parâmetros, entende padrões complexos com poucas palavras. É como um médico experiente que diagnostica por um sintoma leve. Ele não precisa de todo o histórico clínico. Isso tem um impacto direto na prática: se você usa um modelo pequeno, a minimização de dados pode degradar muito a qualidade da resposta. Mas se você usa um modelo grande, pode remover quase tudo e ainda obter ótimos resultados. A diferença é de quase 4,3 vezes. Isso torna a minimização praticamente inviável em modelos abaixo de 7 bilhões de parâmetros - a menos que você os ajuste com técnicas como LoRA, que melhoram essa tolerância em até 31,8%.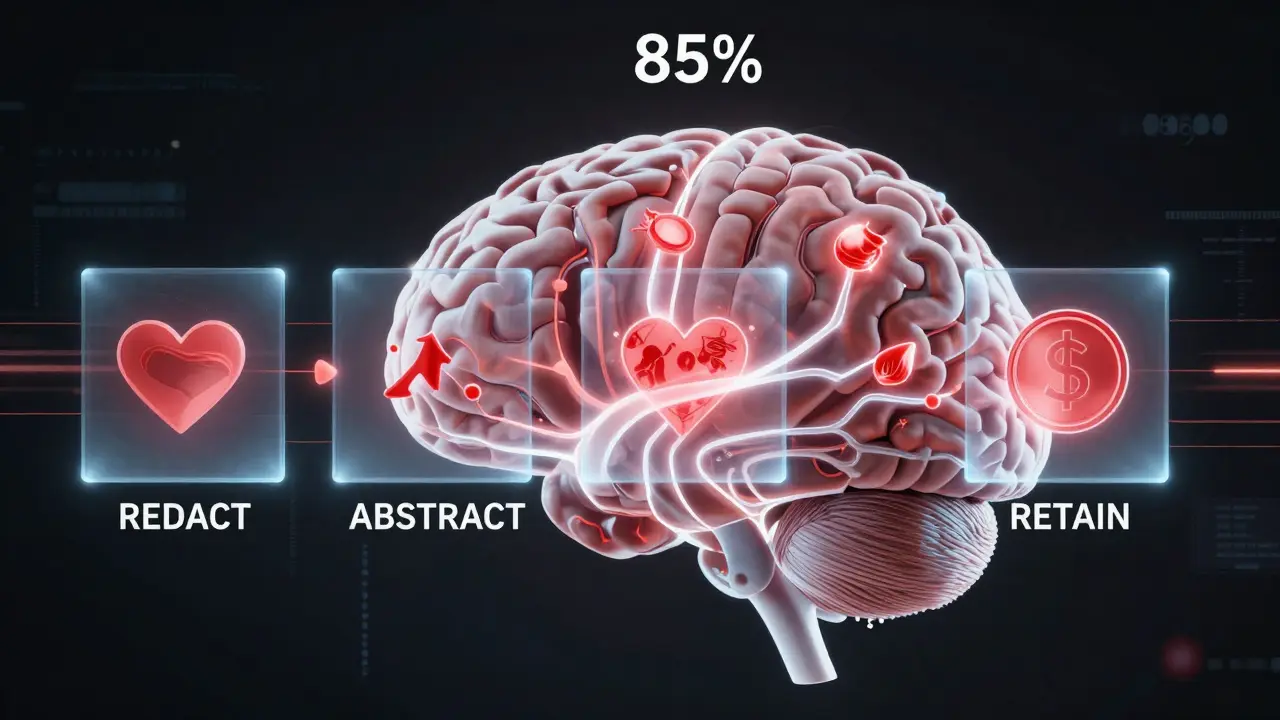
Como implementar na prática?
Se você está desenvolvendo uma aplicação que usa LLMs - seja um chat de saúde, um assistente financeiro ou um sistema de suporte - aqui está o passo a passo real:- Análise prévia do prompt: Use ferramentas como DSPM (Data Security Posture Management) para escanear seu texto e identificar PII (Informações de Identificação Pessoal). Isso detecta CPF, e-mail, telefones, nomes completos.
- Transformação baseada em prioridade: Aplique REDACT primeiro. Depois, se necessário, use ABSTRACT. Nunca use RETAIN a menos que seja absolutamente inevitável.
- Validação da utilidade: Teste a resposta após a minimização. Se a qualidade cair mais de 15%, ajuste. A pesquisa da Carnegie Mellon recomenda manter pelo menos 85% da utilidade original.
Quais ferramentas ajudam?
Há opções abertas e comerciais:- MinimizeLLM (open-source no GitHub): Um toolkit simples que aplica REDACT e ABSTRACT automaticamente. Tem 1.842 estrelas e é gratuito.
- DSPM da Proofpoint: Integra com APIs de LLM e reduz exposição de dados em até 83,7%.
- LoRA fine-tuning: Se você pode treinar seu próprio modelo, essa técnica permite que ele entenda menos dados com maior precisão - e com apenas 8-12% de sobrecarga computacional.

Quais são os riscos de não fazer isso?
Não minimizar dados não é só um erro técnico. É um risco jurídico. A Autoridade Europeia de Proteção de Dados (EDPB) emitiu orientações em abril de 2025 dizendo que coletar mais dados do que o necessário viola o GDPR. No Brasil, a LGPD é igualmente rigorosa. Se você armazena ou processa dados de cidadãos europeus ou brasileiros, e não minimiza, pode ser multado em até 4% da sua receita global. Além disso, há riscos de reputação. Um vazamento de dados por causa de um prompt mal projetado pode destruir a confiança de clientes. E os modelos não são confiáveis nisso. Pesquisas mostram que LLMs tendem a pedir mais dados do que o necessário - 37,4% mais do que o ideal. Eles não sabem o que é privado. Eles só sabem que você deu um monte de informação. Eles vão usar tudo.Como começar hoje mesmo?
Você não precisa de uma equipe de engenheiros ou um orçamento de milhões. Comece assim:- Revise seus prompts atuais. O que você realmente precisa para obter uma resposta útil?
- Substitua nomes por pronomes. "Meu cliente João da Silva" → "meu cliente".
- Remova datas de nascimento, endereços, números de telefone.
- Teste com um modelo grande. Veja se a resposta ainda faz sentido.
- Use ferramentas gratuitas como MinimizeLLM para automatizar.
O futuro da minimização
O mercado de ferramentas de minimização de dados para IA já chegou a US$ 2,78 bilhões em 2024 e cresce 38,7% por ano. Gartner prevê que 70% das empresas usarão protocolos formais de minimização até 2026. O que está em desenvolvimento agora inclui oráculos em tempo real que ajustam a minimização enquanto você digita, e integração com o NIST AI Risk Management Framework - que deve ser lançado em fevereiro de 2025. Mas o verdadeiro avanço não virá de software. Virá de mudança de mentalidade. Parar de pensar "o que posso dar?" e começar a pensar "o que preciso dar?". Porque em um mundo onde modelos de linguagem memorizam tudo, o que você não envia é tão importante quanto o que envia.Minimização de dados reduz a qualidade das respostas dos modelos?
Não necessariamente. Modelos grandes como GPT-4 conseguem manter até 85,7% da qualidade da resposta mesmo quando 85,7% dos dados pessoais são removidos. O segredo está em usar técnicas como REDACT e ABSTRACT, que substituem dados específicos por contextos genéricos. O problema ocorre principalmente com modelos menores, que precisam de mais contexto para funcionar corretamente.
Quais são os principais riscos de usar prompts com muitos dados pessoais?
Três riscos principais: 1) Memorização - o modelo pode armazenar e reproduzir seus dados em respostas futuras; 2) Rastreamento - seus padrões de uso podem ser usados para criar perfis de comportamento; 3) Vazamentos - se o sistema for hackeado, seus dados sensíveis podem ser expostos. Isso viola a LGPD e o GDPR, e pode resultar em multas pesadas.
Posso usar minimização de dados com modelos abertos, como Llama ou Mistral?
Sim, mas com limitações. Modelos menores (abaixo de 7 bilhões de parâmetros) têm menor tolerância à minimização. Eles podem perder até 70% da qualidade se você remover muitos dados. A solução é usar técnicas como LoRA fine-tuning, que ajustam o modelo para entender menos informações com mais precisão, melhorando sua eficiência em até 31,8%.
Quais ferramentas gratuitas posso usar para minimizar dados em prompts?
O toolkit MinimizeLLM, disponível no GitHub, é a melhor opção gratuita. Ele detecta automaticamente PII (como CPF, e-mail, nome completo) e aplica REDACT ou ABSTRACT. Outra opção é usar scripts simples com bibliotecas como spaCy ou NLTK para identificar e remover dados sensíveis antes de enviar ao modelo.
A minimização de dados é obrigatória por lei?
Sim. A LGPD no Brasil e o GDPR na União Europeia exigem que apenas os dados estritamente necessários sejam coletados e processados. Isso se aplica a qualquer sistema que use IA, incluindo LLMs. Se você coleta mais dados do que o necessário para uma tarefa, está em violação da lei - mesmo que não tenha intenção de abusar desses dados.
8 Comentários
Seu post é tipo aquele professor que fala 40 minutos sobre como não usar o lápis errado... mas ninguém liga porque o caderno já tá cheio de rabiscos.
Essa história de minimizar dados é linda... até você tentar usar um LLM pra fazer um relatório de saúde da sua mãe e ele responde: "Desculpe, não tenho contexto suficiente para diagnosticar sua condição respiratória crônica". Aí você lembra que esqueceu de dizer que ela tem asma. O modelo não é burro, é só que você tá tentando ser um herói da privacidade e acabou deixando ele cego.
Isso tudo é uma farsa patrocinada por Big Tech. Você acha que o GPT-4 não sabe seu nome, endereço e o nome do seu cachorro só porque você tirou do prompt? Ele já sabe. Ele aprendeu com seus posts anteriores, seus e-mails, suas buscas no Google. Minimizar dados é como colocar uma máscara num ladrão que já entrou na sua casa. A LGPD não protege ninguém, só dá um falso senso de controle. E quem paga a conta? O usuário. O sistema tá cheio de armadilhas, e vocês só estão arrumando o tapete.
Eu acho que o verdadeiro problema não é a quantidade de dados, mas a nossa relação com a tecnologia. Nós tratamos LLMs como assistentes mágicos, mas esquecemos que eles são espelhos - refletem tudo o que damos, mesmo que não queiramos. A minimização não é uma técnica de segurança, é um exercício de autodomínio. Parar de pensar "o que posso mandar?" e começar a pensar "o que eu realmente quero revelar?". É filosofia. É ética. É quase meditação. E se você não consegue fazer isso com um prompt, como vai fazer com sua vida digital inteira?
Brasil tá perdendo tempo com essa besteira. Enquanto a China e os EUA estão treinando modelos que entendem 90% do que você fala com 10% dos dados, nós aqui discutindo se "criança com condição respiratória crônica" é melhor que "minha filha de 8 anos com asma"? Pode parar. O modelo não liga. O que importa é que o seu sistema de saúde tá falindo e você tá preocupado com privacidade num chatbot. Isso é luxo de quem não tem problema real.
Eu testei isso com um prompt de suporte financeiro: troquei "meu cartão de crédito terminado em 4829" por "cartão de crédito" e a resposta foi 100% útil. O modelo não precisa do número, só do contexto. E aí eu vi que todos os meus prompts antigos eram tipo um diário pessoal. Foi um choque. Não é sobre segurança, é sobre clareza. Menos é mais, mesmo na IA. E isso é fácil de implementar - só precisa de atenção. Não de ferramentas caras.
Se você está usando um modelo pequeno e acha que minimizar dados é impossível, você não entendeu o problema. O problema não é o modelo. É você que tá usando ele como se fosse um psicólogo. LLMs não são terapeutas. Eles são ferramentas de reconhecimento de padrões. Se você quer que eles funcionem com poucos dados, pare de pedir para eles adivinharem sua vida. Dê contexto, não confissão. E se não sabe como? Treine. Não espere que a ferramenta seja perfeita. Seja você.
Então... se eu digo "meu cliente" em vez de "João da Silva", o modelo vai entender que ele é um homem de 45 anos, casado, com dívida no SPC e que odeia café? 😏
Porque aí a minimização é só um jogo de adivinhação... e eu tô aqui achando que estou protegido, mas na verdade tô só deixando o modelo mais criativo com os meus vazamentos.