



Se você já usou um modelo de IA para analisar desempenho de sistemas, aplicativos ou até processos de negócios, provavelmente já percebeu que o resultado depende muito do que você pede. Um prompt vago como "melhore isso" gera respostas genéricas, sem valor real. Mas um prompt bem construído pode entregar um plano de otimização detalhado, com passos concretos, métricas e até prioridades. A diferença entre um bom e um ótimo prompt está nos detalhes - e isso não é mágica, é técnica.
Entenda o que você está tentando medir
Antes de escrever qualquer prompt, você precisa saber exatamente o que está sendo analisado. Você quer otimizar o tempo de resposta de uma API? Reduzir o uso de memória em um modelo de linguagem? Aumentar a taxa de conversão de um chatbot? Cada objetivo exige um tipo diferente de dados e uma abordagem distinta.Se você não define isso claramente, a IA vai tentar adivinhar - e provavelmente vai errar. Por exemplo, pedir "otimize o desempenho do sistema" sem contexto pode gerar sugestões sobre rede, código, hardware ou até UX. Isso não ajuda. Em vez disso, seja específico: "O sistema de recomendação da nossa plataforma está demorando mais de 2,3 segundos para responder. O modelo usa 12 GB de RAM e processa 800 requisições por minuto. Como reduzir o tempo de resposta para abaixo de 800 ms sem aumentar o custo?"
Essa estrutura - contexto, métrica atual, limite desejado - é o mínimo absoluto para obter respostas úteis. A IA não sabe o que é "rápido" ou "lento" se você não disser.
Use a estrutura de cinco partes para prompts de profiling
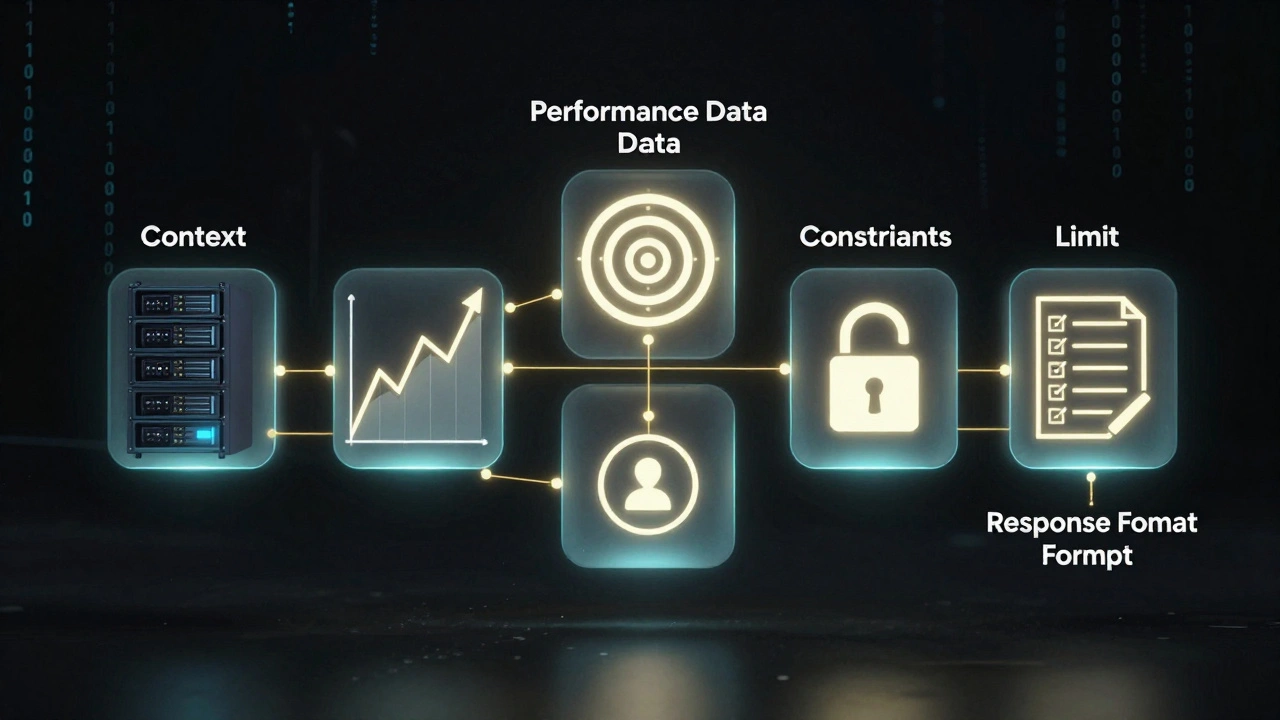
Um prompt eficaz para análise de desempenho segue uma estrutura simples, mas poderosa:- Contexto: O que está sendo analisado? (ex: API REST, modelo de IA, aplicativo móvel)
- Dados de desempenho: Métricas reais (tempo, uso de CPU, latência, erro por segundo, custo por requisição)
- Limite ou meta: O que é considerado aceitável? (ex: "queremos 95% das requisições abaixo de 500 ms")
- Restrições: O que você NÃO pode mudar? (ex: não pode migrar para outro provedor, não pode aumentar o orçamento)
- Formato de resposta: O que você quer? (lista de ações, tabela de prioridades, código de exemplo, gráfico sugerido)
Um prompt bem feito com essa estrutura pode ser assim:
"O sistema de autenticação da nossa app móvel está com uma latência média de 1,8 segundos. 30% das requisições falham com erro 504. O sistema roda em um servidor AWS t3.medium, com 2 GB de RAM. O orçamento não permite upgrade de hardware. Queremos reduzir a latência para abaixo de 600 ms e manter a taxa de falha abaixo de 5%. Forneça um plano de otimização com até 5 ações práticas, priorizadas por impacto e custo. Inclua exemplos de código ou configuração se possível."
Repare que esse prompt não deixa espaço para ambiguidade. Ele fornece dados reais, limites claros e até o formato esperado. Isso faz toda a diferença.
Evite esses erros comuns em prompts de otimização
Muitas pessoas acreditam que quanto mais detalhado o prompt, melhor. Mas isso não é verdade. O excesso de informação pode confundir a IA. Aqui estão os erros mais frequentes:- Usar jargões sem explicar: "O modelo está sofrendo com overfitting no batch de treinamento" - se você não explicar o que isso significa para o sistema, a IA não vai saber como ajudar.
- Não dar valores reais: "O sistema está lento" - isso é subjetivo. Diga: "A média é 3,2s, o SLA é 1,5s".
- Esperar que a IA adivinhe o ambiente: "Como otimizar o Python?" - Python roda em centenas de ambientes diferentes. Qual versão? Qual framework? Qual banco de dados?
- Pedir soluções genéricas: "Dê dicas de otimização" - isso gera listas de 20 itens, metade irrelevante.
Quando você pede algo como "como melhorar o desempenho do meu chatbot?", a IA responde com uma lista de 15 técnicas genéricas: "use cache", "otimize o modelo", "reduza o contexto". Isso não é útil. Você quer ações específicas para o seu caso.
Exemplo real: otimizando um modelo de linguagem
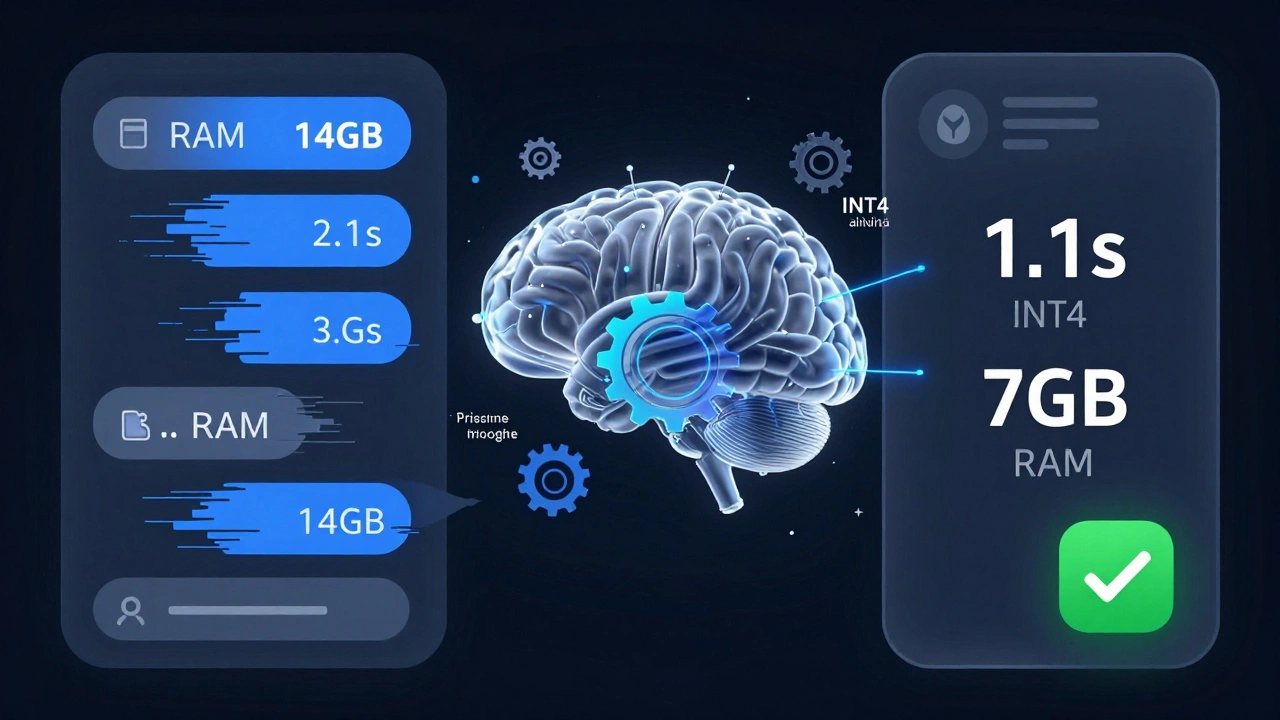
Suponha que você tenha um modelo de linguagem usado para responder perguntas de clientes. Ele está consumindo 14 GB de RAM e demorando 2,1 segundos por resposta. O custo por chamada está subindo. Você quer manter a qualidade da resposta, mas reduzir custo e latência.Um bom prompt seria:
"Estou usando o modelo Llama 3 8B para responder perguntas de clientes em um chatbot. O modelo roda em um servidor com 16 GB de RAM e 4 vCPUs. A latência média é de 2,1 segundos. O uso de memória é de 14 GB por instância. A taxa de erro de resposta é de 8%. Quero reduzir o uso de memória para abaixo de 8 GB e a latência para abaixo de 1,2 segundos, sem perder mais de 2% na qualidade das respostas. O orçamento não permite trocar o hardware. Forneça um plano com até 4 ações práticas, priorizadas por impacto. Inclua configurações de quantização, técnicas de pruning, e sugestões de modelo menor que mantenha a qualidade. Se possível, compare o impacto de cada técnica em termos de memória, latência e precisão."
Com esse prompt, a IA não vai te dar um texto genérico. Ela vai te dizer, por exemplo:
- Use quantização INT4 - reduz o uso de memória em 50% com perda de 1,2% na precisão.
- Reduza o contexto de 4096 para 2048 tokens - corte de 30% na latência.
- Troque o Llama 3 8B por Mistral 7B - 30% menos memória, 15% mais rápido, mesma qualidade em testes de QA.
- Implemente cache de respostas para perguntas repetidas - reduz custo em até 40%.
Essa é a diferença entre um prompt que funciona e um que só ocupa espaço.
Como validar as sugestões da IA
Nem toda sugestão da IA é boa. Ela pode sugerir técnicas que não funcionam no seu ambiente, ou que exigem mudanças que você não pode fazer. Sempre valide antes de implementar.Use este checklist:
- Os dados são reais? A IA baseou sua análise em métricas que você forneceu? Se não, desconfie.
- As soluções são viáveis? Elas exigem mudança de infraestrutura que você não pode fazer? Se sim, ignore.
- Tem métricas de impacto? A sugestão diz "reduz em 30%"? Isso é bom. Se ela só diz "melhora o desempenho", é vazio.
- Existe evidência? A IA menciona técnicas como "quantização INT4" ou "pruning de camadas"? Isso mostra que ela entende o assunto. Se ela só fala em "otimize o código", é genérico.
Se a IA sugerir uma técnica nova, pesquise rapidamente: "quantização INT4 Llama 3". Se aparecerem artigos da Hugging Face, NVIDIA ou arXiv, é confiável. Se não, pode ser chute.
Use a IA como assistente, não como substituto
A IA não substitui um engenheiro de desempenho. Mas ela pode ser o seu primeiro assistente. Ela não sabe o que acontece no seu servidor, mas pode processar padrões, comparar técnicas e sugerir caminhos que você nunca considerou.Use-a para:
- Gerar opções de otimização baseadas em dados reais
- Comparar trade-offs entre diferentes abordagens
- Identificar técnicas que você não conhece
- Escrever o primeiro rascunho de um plano de ação
Mas nunca implemente sem testar. Faça um teste A/B. Monitore antes e depois. Anote métricas. Se a latência caiu, mas a taxa de erro subiu, você trocou um problema por outro.
Próximos passos: como começar hoje
Se você quer começar a usar prompts para profiling e otimização, aqui está o que fazer agora:- Escolha um sistema que está lento, caro ou instável.
- Reúna as 3 métricas mais importantes: tempo, uso de recursos, taxa de erro.
- Defina um objetivo realista: "quero reduzir o tempo em 40% em 30 dias".
- Escreva um prompt usando a estrutura de 5 partes.
- Execute e anote as sugestões.
- Teste a melhor sugestão em um ambiente de teste.
- Meça o impacto real.
Isso não é teoria. É o que empresas de tecnologia em Porto Alegre, São Paulo e até em startups no Vale do Silício estão fazendo todos os dias. Não precisa ser um especialista. Só precisa ser claro, preciso e paciente.
Como a IA entende otimização?
A IA não "entende" desempenho como um humano. Ela reconhece padrões. Ela sabe que, em milhares de casos, reduzir o tamanho do contexto em modelos de linguagem diminui a latência. Ela sabe que quantização INT4 reduz o uso de memória em modelos de IA. Ela não sabe o que é o seu servidor - mas ela sabe o que funciona em sistemas parecidos.Seu trabalho é fornecer o contexto. O resto, ela faz. E isso, na prática, é o que separa quem usa IA como ferramenta e quem a usa como bruxaria.
O que é um prompt de profiling de desempenho?
Um prompt de profiling de desempenho é uma instrução específica que pede à IA para analisar métricas de velocidade, uso de recursos ou eficiência de um sistema, e sugerir melhorias baseadas em dados reais. Ele vai além de "melhore isso" - fornece contexto, números, limites e o formato esperado da resposta.
Posso usar esse método com qualquer modelo de IA?
Sim. Funciona com GPT, Claude, Llama, Mistral, ou qualquer outro modelo de linguagem. O que importa não é o modelo, mas a qualidade do prompt. Modelos maiores podem entender melhor detalhes técnicos, mas até modelos menores conseguem entregar respostas úteis se o prompt for claro e bem estruturado.
Como saber se a sugestão da IA é confiável?
Verifique se a resposta menciona técnicas específicas (como quantização, pruning, cache de respostas), dá números de impacto ("reduz 30% da latência") e se alinha com sua realidade (não pede upgrade de hardware se você não pode fazer). Pesquise rapidamente as técnicas sugeridas - se aparecerem em fontes como Hugging Face, arXiv ou documentação oficial, é confiável.
Qual é o pior erro ao fazer esses prompts?
O pior erro é ser vago. Frases como "otimize o sistema" ou "melhore o desempenho" geram respostas genéricas que não servem para nada. A IA não lê mentes. Ela precisa de dados, limites e objetivos claros para entregar algo útil.
Preciso ser programador para usar isso?
Não. Você precisa entender o que está sendo analisado - se é um site, um chatbot, uma API - e ter acesso às métricas básicas. Se você consegue dizer "demora 3 segundos para carregar" e "custa R$ 120 por mês", já tem o mínimo necessário. A IA vai te ajudar a entender o que fazer com esses números.
13 Comentários
Realmente, o segredo é não deixar a IA adivinhar. Já testei isso com um chatbot de atendimento e depois que comecei a colocar os números exatos, as respostas mudaram completamente. Antes era só papo furado, agora tem ação direta.
mano... isso aqui é ouro puro... mas 90% das pessoas vão ler até o título e depois dizer 'ah, mas eu não sou técnico'... sério, isso aqui é o que separa os que usam IA de quem só usa pra fazer piada no grupo do whatsapp
Essa parte do checklist de validação é a que mais falta. Já vi gente implementar sugestão da IA e depois o sistema cair no ar. Aí vem o clássico: 'mas a IA disse que funcionava'... Não, ela disse que podia funcionar. Tem que testar, caralho.
Se não colocar os números é só perda de tempo. Já fiz isso com um sistema de recomendação e pedi 'melhore o desempenho'. Resultado? 'Use cache'. Obrigado, Sherlock.
Essa galera que acha que IA é mágica vai continuar perdendo tempo. Se você não sabe o que medir, não merece usar ferramentas. É como pedir para um médico curar sem dizer onde dói. A IA não é seu assistente espiritual.
Em Portugal já fazemos isso desde 2021... aqui ninguém perde tempo com 'otimize isso'. Se você não sabe medir, não merece estar no mercado. Isso aqui é básico, sério. Vocês no Brasil ainda estão no 'use o GPT pra fazer resumo de aula'?
Quem escreve isso acha que é gênio. Mas a verdade é que qualquer um que leu um artigo de engenharia de software já sabia disso. A IA só tá repassando o que já existe. Não é inovação, é repetição com outro nome.
Isso aqui é exatamente o que precisamos mais no mercado: clareza. Não é sobre ser técnico, é sobre ser preciso. Já usei isso com time de marketing e eles conseguiram otimizar campanhas só com métricas simples. A IA não é o problema, a gente é.
eu ja tentei isso e deu ruim. a ia sugeriu trocar o banco de dados e o sistema caiu. agora to sem trabalho. obrigado, IA.
ah sim claro, porque ninguém nunca pensou nisso antes. só você e esse post que descobriram que IA precisa de instrução clara. parabéns, você é o primeiro ser humano da história a entender isso.
Isso aqui é o fim da humanidade. Antes a gente pensava, agora só copia prompts. A IA tá nos tornando preguiçosos, cegos, sem senso crítico. Vocês estão trocando o cérebro por um template. E ainda chamam isso de progresso?
EU NÃO QUERO SABER DE PROMPTS! EU QUERO QUE A IA LEIA MINHA MENTE! POR QUE VOCÊS NÃO ENTENDEM QUE EU SOU DIFERENTE?! MEU SISTEMA É ÚNICO! NÃO É SÓ COPIAR E COLAR! EU TENHO ALMA E A IA NÃO ENTENDE ALMA!
Essa estrutura de 5 partes realmente muda tudo. Eu usei com uma equipe de suporte técnico que nunca tinha mexido com IA antes e, em duas semanas, eles conseguiram reduzir o tempo de resolução de chamados em 40%. O segredo não é a tecnologia, é a disciplina de definir o problema antes de pedir ajuda. A IA é um espelho: ela reflete o que você coloca. Se você for vago, ela devolve vazio. Se você for claro, ela devolve valor. Isso não é só técnica, é uma mudança de mentalidade. E é isso que realmente importa - não o modelo, não o hardware, mas a intenção por trás da pergunta.