


Você já pediu uma resposta específica ao seu assistente de IA e recebeu uma confabulação convincente? É frustrante. Modelos de linguagem grandes (LLMs) são impressionantes, mas eles têm um problema grave: alucinação. Eles inventam fatos porque dependem apenas do que viram durante o treinamento, que é estático e limitado. A solução que as empresas estão adotando em 2026 não é treinar o modelo novamente. É conectar o modelo a seus próprios dados em tempo real. Essa arquitetura chama-se RAG (Retrieval-Augmented Generation) ou Geração Aumentada por Recuperação.
O RAG funciona como uma memória externa para a IA. Em vez de confiar na "memória" treinada do modelo, o sistema busca informações precisas em um banco de dados antes de gerar a resposta. Mas para que isso funcione rápido e sem erros, você precisa entender três pilares técnicos: embeddings, indexação HNSW e filtros de metadados. Sem essa base técnica, seu sistema será lento ou impreciso.
O Que São Embeddings e Por Que Eles Importam?
Para que uma IA entenda texto, ela precisa transformar palavras em números. Esses números são os embeddings. Um embedding é uma representação matemática de um pedaço de texto (ou imagem) convertida em um vetor de alta dimensão - basicamente, uma lista longa de números que captura o significado semântico.
Pense nisso como coordenadas GPS, mas para conceitos. Palavras com significados semelhantes ficam próximas no espaço multidimensional. Se você usar o modelo popular all-MiniLM-L12-v2 da biblioteca SentenceTransformers, cada trecho de texto se torna um vetor de 384 dimensões. Quando você faz uma pergunta, o sistema converte sua pergunta no mesmo tipo de vetor. O banco de vetores então procura os vetores mais próximos do seu. Quanto menor a distância angular (similaridade cosseno), mais relevante é o conteúdo recuperado.
A escolha do modelo de embedding é crítica. Modelos como o Amazon Titan Text Embedding v2 são otimizados para produção, enquanto opções open-source funcionam bem para protótipos. O segredo é manter consistência: use sempre o mesmo modelo para indexar seus documentos e para processar as consultas dos usuários. Se misturar modelos diferentes, os vetores estarão em espaços semânticos incompatíveis, e a recuperação falhará.
Bancos de Vetores: A Memória de Longo Prazo da IA
Um banco de dados relacional tradicional, como MySQL ou PostgreSQL puro, não foi feito para isso. Ele busca correspondências exatas. Se você perguntar "carro barato", ele só encontrará resultados que contenham exatamente essas palavras. Um banco de vetores, porém, entende contexto. Ele pode encontrar um documento sobre "veículos econômicos" mesmo que as palavras exatas não batam.
Bancos de vetores são infraestrutura especializada projetada para armazenar milhões ou bilhões de embeddings e realizar buscas de similaridade em milissegundos. Exemplos incluem Pinecone, Milvus e extensões como Pgvector para PostgreSQL. No cenário brasileiro e global, muitas empresas optam pelo Pgvector porque permite manter os dados estruturados e os vetores no mesmo lugar, simplificando a governança.
A estrutura básica de uma tabela de embeddings geralmente inclui:
- Um identificador único (ID).
- O vetor em si (com dimensões fixas, ex: 384 ou 1536).
- O conteúdo original ou referência ao documento.
- Metadados para filtragem (autor, data, categoria).
Manter os embeddings perto dos dados de origem reduz latência e complexidade. Ferramentas como Aurora ML permitem gerar esses vetores diretamente dentro do banco via procedimentos armazenados, eliminando a necessidade de pipelines externos complexos para transformações iniciais.

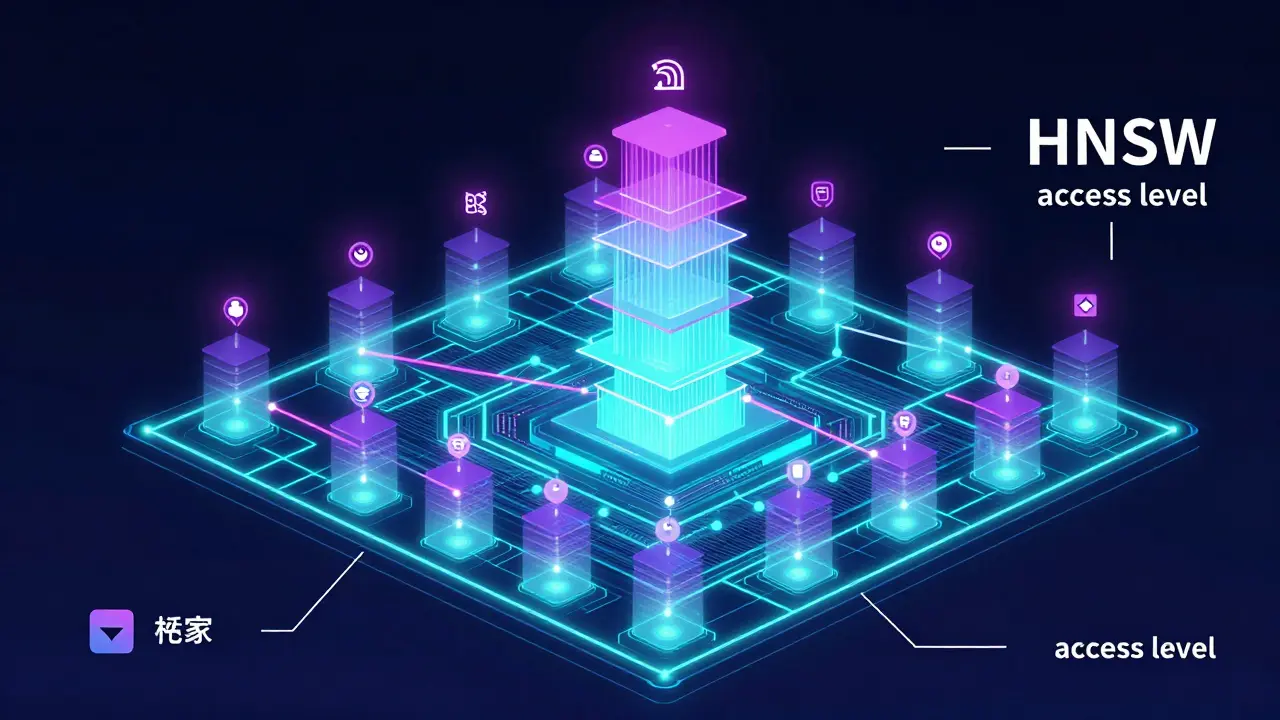
HNSW: O Motor de Velocidade do RAG
Armazenar vetores é fácil. Encontrar o mais parecido entre dez milhões deles rapidamente é difícil. Uma busca linear (verificar cada vetor um por um) levaria segundos ou minutos. Isso mata a experiência do usuário. É aqui que entra o HNSW (Hierarchical Navigable Small World).
O HNSW é um algoritmo de indexação baseado em grafos. Imagine uma cidade vista de um avião. As estradas principais conectam regiões distantes rapidamente (camadas superiores do grafo). À medida que você desce, vê ruas menores que levam a bairros específicos (camadas inferiores). O HNSW cria essa hierarquia artificial nos seus dados.
Quando uma consulta chega, o algoritmo começa nas camadas superiores, saltando rapidamente pela "cidade" dos dados até chegar perto do alvo. Depois, ele desce para camadas mais detalhadas para refinar a busca. Esse método oferece um equilíbrio poderoso entre velocidade e precisão (recall).
Dados reais demonstram o impacto. Em testes com PostgreSQL + Pgvector contendo 1 milhão de registros de 384 dimensões, a construção do índice HNSW levou cerca de 33 minutos. Porém, o tempo de busca caiu de vários segundos para meros milissegundos. É uma melhoria de desempenho superior a 100 vezes. Para aplicações empresariais onde a resposta deve ser instantânea, o HNSW é frequentemente a escolha padrão sobre alternativas como IVFFlat, que usa particionamento geométrico mas pode ter recall ligeiramente inferior em certos cenários.
Filtros: Adicionando Lógica de Negócio à Busca Semântica
Semântica sozinha não basta. Imagine um sistema de suporte técnico. Um usuário pergunta sobre "erro de login". O RAG encontra o artigo perfeito. Mas esse artigo é para clientes do Plano Premium, e o usuário atual tem o Plano Básico. Se o sistema retornar aquele artigo, você violou regras de negócio.
Aqui entram os filtros de metadados. Eles permitem restringir a busca vetorial a subconjuntos de dados com base em critérios lógicos. Você pode filtrar por:
- Tenant ID (para aplicações multi-inquilino).
- Data de validade do documento.
- Nível de acesso do usuário.
- Categoria ou departamento.
O banco de vetores aplica esses filtros antes ou durante a busca de similaridade. Isso garante que os resultados não sejam apenas semanticamente relevantes, mas também contextualmente apropriados e seguros. A combinação de busca vetorial aproximada com filtros exatos é o que torna o RAG viável para ambientes corporativos rigorosos.
| Método | Velocidade de Leitura | Precisão (Recall) | Uso de Memória | Melhor Para |
|---|---|---|---|---|
| HNSW | Muito Alta | Alta | Elevado | Aplicações em tempo real, baixa latência |
| IVFFlat | Alta | Moderada a Alta | Moderado | Conjuntos de dados muito grandes, orçamento limitado |
| Busca Linear (Brute Force) | Muito Baixa | Perfeita | Baixo | Prototipagem, conjuntos pequenos (<10k vetores) |
Como Implementar RAG na Prática
Implementar RAG exige atenção aos detalhes. Aqui está um fluxo simplificado:
- Chunking (Fragmentação): Divida seus documentos longos em pedaços menores e semanticamente coerentes. Evite cortar frases ao meio. Pedaços de 500-1000 tokens são comuns.
- Embedding: Use um modelo consistente para converter cada chunk em um vetor. Armazene-o junto com o texto original e metadados.
- Indexação: Crie um índice HNSW nos vetores para acelerar buscas futuras.
- Consulta: Quando o usuário pergunta, converta a pergunta em vetor. Execute a busca de similaridade no banco, aplicando filtros necessários.
- Geração: Pegue os top-k chunks mais relevantes e insira-os no prompt do LLM como contexto. Peça ao modelo para responder usando apenas essas fontes.
Uma dica profissional: monitore a qualidade dos chunks. Se um chunk for muito genérico, ele polui os resultados. Se for muito específico, pode perder o contexto necessário. Teste diferentes tamanhos de chunk e sobreposições (overlap) para encontrar o equilíbrio ideal para seu domínio.
Reduzindo o Risco de Alucinação
O objetivo final do RAG é reduzir alucinações. Ao fornecer ao LLM fontes verificáveis e atuais, você limita sua capacidade de inventar. No entanto, o RAG não elimina completamente o risco. O modelo ainda pode ignorar o contexto se o prompt não for bem engenhado.
Use instruções claras no prompt: "Responda apenas com base no contexto fornecido abaixo. Se a resposta não estiver no contexto, diga 'Não tenho informação suficiente'." Isso força o modelo a depender da recuperação. Além disso, cite as fontes na resposta final para aumentar a transparência e confiança do usuário.
A combinação de embeddings precisos, indexação rápida via HNSW e filtros robustos cria um sistema de IA que não apenas parece inteligente, mas é factualmente confiável. Em 2026, essa não é mais uma opção experimental; é o padrão para qualquer aplicação séria de IA generativa empresarial.
O que é RAG e por que é importante?
RAG (Retrieval-Augmented Generation) é uma técnica que combina a geração de texto de um LLM com a recuperação de dados externos. É importante porque resolve dois problemas principais dos LLMs: alucinação (invenção de fatos) e conhecimento desatualizado, permitindo que a IA responda com base em dados proprietários e recentes.
Qual a diferença entre HNSW e IVFFlat?
HNSW é um algoritmo baseado em grafos que oferece alta velocidade e precisão, mas consome mais memória. IVFFlat usa particionamento geométrico, sendo mais leve em memória, mas podendo ter ligeiramente menos precisão em alguns casos. HNSW é preferido para latência ultra-baixa.
Por que usamos embeddings em vez de busca por palavras-chave?
A busca por palavras-chave depende de correspondência exata. Embeddings capturam o significado semântico. Isso significa que uma busca por "carro econômico" encontrará documentos sobre "veículos eficientes em combustível", mesmo que as palavras não coincidam literalmente.
Os filtros de metadados afetam a performance da busca?
Sim, podem. Filtros complexos podem adicionar latência. No entanto, bancos de vetores modernos otimizam isso combinando índices de metadados com a busca vetorial. É crucial testar a performance com filtros ativos para garantir que a experiência do usuário permaneça fluida.
Posso usar PostgreSQL para armazenar embeddings?
Sim, através da extensão Pgvector. Ela adiciona suporte nativo a tipos de dados vetoriais e operadores de similaridade (como cosseno e euclidiano) ao PostgreSQL, tornando-o uma opção viável e integrada para muitos times de desenvolvimento.
15 Comentários
Vocês ainda estão lá com essa dependência de tecnologia americana? Pinecone, Milvus, tudo isso é feito por gringos para nos controlar. O Brasil deveria ter seus próprios bancos de vetores nacionais, feitos por engenheiros brasileiros, não por essas multinacionais que só querem nossos dados. É vergonhoso ver a elite tech aqui aplaudindo qualquer coisa que venha de fora sem questionar a soberania tecnológica. Precisamos parar de ser colonizados digitalmente e criar soluções locais agora mesmo.
Exatamente. A questão da soberania é fundamental. Além disso, a maioria desses 'especialistas' nem entende o básico de como o HNSW funciona internamente, apenas copiam colam tutoriais do Stack Overflow. Sem um entendimento profundo da matemática por trás dos grafos navegáveis, o sistema vai falhar em escala. É preciso rigor técnico, não modinha.
Mas será que a verdadeira alucinação não está na nossa própria percepção da realidade? Se a IA reflete os vieses dos dados humanos, então ela não está inventando, apenas espelhando nossa própria confusão existencial. O RAG tenta impor uma estrutura lógica rígida sobre um caos semântico inerente à linguagem humana. Talvez a busca pela precisão absoluta seja uma ilusão filosófica em si mesma. O que significa ser 'correto' quando o significado é fluido?
Oi pessoal! Que conteúdo incrível sobre RAG! 😊 Eu acho que a parte sobre chunking é super importante porque se você cortar as frases no meio, perde todo o sentido. Vamos juntos nessa jornada de aprendizado contínuo! Nunca parem de estudar novas tecnologias. A consistência nos embeddings é chave para o sucesso do projeto.
Ah, claro, mais um tutorial genérico sobre RAG 🙄. Como se todos soubessem implementar filtros de metadados corretamente. Na prática, ninguém testa a latência real com milhões de registros. Ficam felizes com protótipos que funcionam no laptop. Spoiler: vai travar em produção. 😒
Que horror ler tanta imprecisão técnica disfarçada de artigo técnico. Primeiramente, a similaridade cosseno não mede distância angular diretamente, ela mede o cosseno do ângulo entre os vetores. Segundo, afirmar que Pgvector é a solução definitiva ignora completamente a complexidade de gerenciamento de índices HNSW em tabelas massivas. Vocês estão simplificando demais para leigos, o que é perigoso. A ortografia também poderia melhorar, mas digamos que a preguiça intelectual seja o maior erro aqui.
Em Portugal, vemos muitas empresas a tentar implementar isto sem perceber que a infraestrutura base não suporta. O problema não é o algoritmo, é a cultura organizacional. Eles querem inteligência artificial mas tratam os dados como lixo. Sem governança, o RAG é apenas um gerador de mentiras mais rápido. É triste ver tanta esperança depositada em ferramentas mágicas.
Eu só queria saber se alguém já testou o Amazon Titan v2 comparado ao open source? Estou curiosíssima para ver a diferença de custo 😊✨ Parece complicado demais pra mim, mas é fascinante ver como os números representam palavras. Alguém tem algum exemplo simples?
GENTE!!! VOCÊS NÃO VÃO ACREDITAR NO QUE EU VI! Testei esse esquema de HNSW no meu banco de dados pessoal e foi UM CAOS TOTAL! Demorou horas pra indexar e depois deu erro de memória. Será que eu fiz algo errado ou é tudo mentira? Preciso de ajuda urgente porque meu chefe tá cobrando resultado amanhã de manhã!!! 😱😱😱
Estou lendo com atenção. A parte sobre a construção do índice levar 33 minutos me chamou a atenção. Isso é aceitável para atualizações frequentes? Ou só vale para cargas iniciais? Gostaria de entender melhor o trade-off entre velocidade de escrita e leitura nesse contexto específico de documentos jurídicos.
vcs sao muito boba nao entendo pq fala tanto. eu uso so google e pronto. embedding ta tudo errado na minha opniao. quem precisa de banco de vetor eh q n sabe programar direito. faz um script python simples e resolve. pq complicar tao desnecessariamente??
Outro post longo pra dizer nada novo. Já vi mil tutoriais assim. Ninguém fala da dor de cabeça de manter os vetores sincronizados com os dados originais. É um pesadelo de engenharia de software. E aí vem um influencer tech dizendo que é fácil. Mentira pura. Perdi duas semanas tentando fazer o recall subir acima de 90% com filtros ativos. Desistam.
Pessoal...; vejam bem...; o HNSW...; não é...; a única opção...; existem outros métodos...; como o IVFFlat...; que podem ser...; mais eficientes...; dependendo do caso...; não deixem...; que ninguém...; dite o que...; é melhor...; para vocês...; façam testes...; por conta própria...;
Interessante. Às vezes penso que estamos criando sistemas que entendem menos do que imaginamos. Outros momentos, vejo a utilidade prática imediata. Depende do contexto. Não tenho opinião forte, só observo.
Olá a todos! Acho que podemos encontrar um meio termo entre a otimização extrema e a simplicidade excessiva. É importante lembrarmos que cada empresa tem suas necessidades únicas, e o que funciona para uma startup pode não servir para uma grande corporação. Vamos colaborar compartilhando experiências reais, respeitando as diferentes abordagens técnicas. Acredito que, juntos, podemos construir sistemas mais robustos e inclusivos, considerando tanto a performance quanto a manutenibilidade a longo prazo, sempre priorizando a clareza e a documentação adequada para facilitar o trabalho das equipes futuras.