




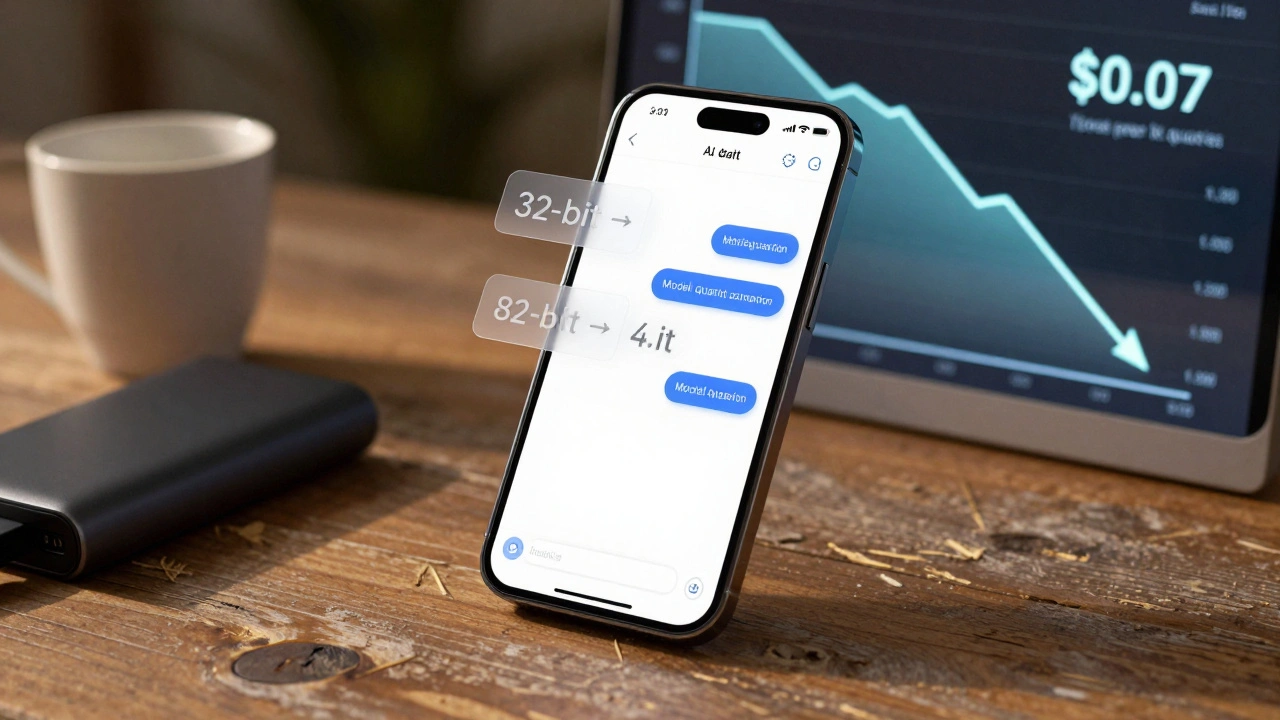
Se você já usou um chatbot que responde rápido mesmo em um celular antigo, ou viu uma empresa cortar sua conta de IA de $1.20 para $0.07 por mil consultas, saiba: isso não é mágica. É compressão de modelos. E a economia por trás disso está mudando quem pode usar grandes modelos de linguagem - e como.
Por que LLMs tão caros?
Modelos como Llama-2, GPT-3 ou Gemma têm bilhões de parâmetros. Isso significa que, para rodar uma única resposta, o sistema precisa fazer trilhões de cálculos. Em nuvem, isso vira conta de servidor gigante. Em dispositivos móveis, vira bateria esgotada em minutos. Aí entra a pergunta real: como manter a qualidade sem pagar o preço de um supercomputador?A resposta está em duas técnicas: quantização e distilação. Nenhuma delas é nova, mas juntas, em 2025, estão tornando LLMs acessíveis para startups, desenvolvedores e até aplicações em países com infraestrutura limitada.
Quantização: o que é e por que funciona
Imagine que um modelo armazena cada número com 32 dígitos de precisão - como usar uma régua milimetrada para medir o tamanho de um grão de areia. A quantização é como trocar essa régua por uma de centímetros. Você perde detalhe, mas ainda consegue ver a diferença entre um grão e uma pedra.Na prática, isso significa transformar números de ponto flutuante de 32 bits (FP32) em inteiros de 8 bits (INT8), 4 bits (INT4) ou até 2 bits. Cada redução corta o tamanho do modelo. Um modelo de 7 bilhões de parâmetros em FP32 ocupa cerca de 28 GB. Em INT8, cai para 7 GB. Em INT4, para 3,5 GB. E em 2-bit? Cerca de 1,7 GB.
Essa redução não é só de espaço. Ela acelera a execução. GPUs modernas, como as da série NVIDIA Ampere ou chips Apple M-series, têm circuitos otimizados para operações de baixa precisão. Resultado? Até 3,8x mais rápido em inferência - e até 80% menos gasto com energia.
Mas tem um porém. Em 2-bit, modelos começam a errar em tarefas complexas. Um estudo da Nature em 2025 mostrou que a precisão cai 12,7% em tarefas que exigem raciocínio fino, como tradução ou análise de sentimentos sutis. Isso porque números muito truncados perdem nuances - e modelos esquecem padrões raros, como palavras pouco usadas ou estruturas gramaticais incomuns.
Por isso, a maioria dos engenheiros hoje usa INT8 como padrão. É o ponto de equilíbrio: perda de precisão menor que 1%, redução de tamanho de 4x, e compatibilidade quase universal com hardware recente. Técnicas como SmoothQuant, desenvolvidas em 2024, melhoram ainda mais isso: elas movem os “outliers” (valores estranhos) dos cálculos dinâmicos para os pesos estáticos, aumentando a acurácia de modelos 4-bit em até 5,2%.
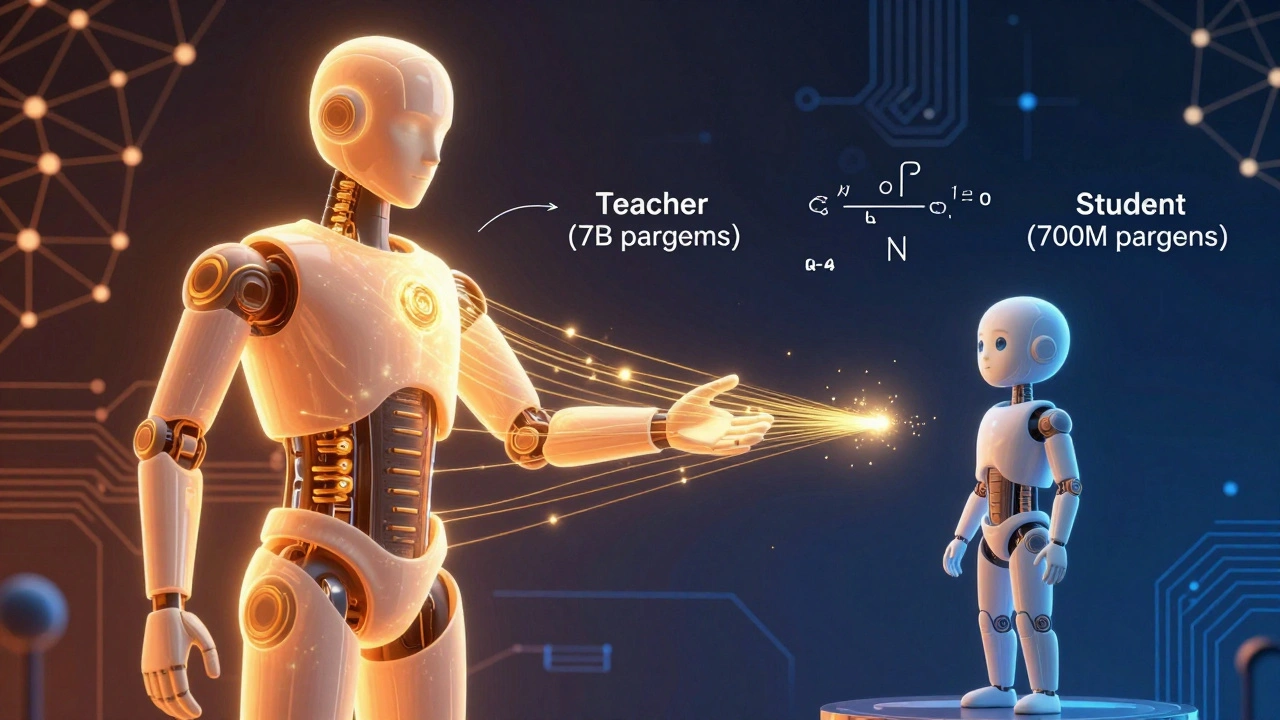
Distilação: ensinar um aluno pequeno a agir como um mestre
A distilação de conhecimento funciona como um treinamento de mentoria. Um modelo grande - o professor - responde milhares de perguntas. Um modelo pequeno - o aluno - observa essas respostas, aprende não só o que ele disse, mas como ele chegou lá: a confiança, o tom, os padrões de raciocínio.Isso não é copiar. É aprender a pensar como o professor. Um modelo de 7 bilhões de parâmetros pode ser distilado para um de 700 milhões - ou até 140 milhões - mantendo 95% da performance. A Amazon mostrou em 2022 que um modelo BART distilado chegou a 1/28 do tamanho original, com 97% da acurácia em respostas de perguntas.
A vantagem? O modelo final é leve o suficiente para rodar em smartphones, carros ou sensores IoT. Google usou isso para criar o GEMMA on-device: um modelo de 2 bilhões de parâmetros, distilado e otimizado, que roda localmente no celular sem precisar de internet.
Mas o custo está no treinamento. Para treinar um aluno, você precisa passar trilhões de tokens pelo professor. O projeto Gemma-2 9B, em 2024, exigiu 8 trilhões de tokens - o equivalente ao treinamento completo de um modelo original. Isso exige centenas de GPUs e semanas de processamento. Só empresas com recursos pesados conseguem fazer isso do zero.
Por isso, muitos usam modelos pré-distilados da Hugging Face, que já oferecem versões compactas de Llama, Mistral e Gemma. É mais barato e rápido. Mas ainda assim, 41% dos desenvolvedores nos fóruns da Hugging Face relatam dificuldades em replicar a qualidade do professor quando o aluno tem menos de 1 bilhão de parâmetros. O chamado “precipício de precisão” acontece: em certos níveis de compressão, a performance despenca.
Quantização + Distilação: a combinação vencedora
Ninguém mais usa uma técnica sozinha. O estado da arte hoje é a combinação. Primeiro, distila-se o modelo para reduzir o tamanho. Depois, aplica-se quantização para apertar ainda mais.Um estudo da Amazon em 2022 mostrou que, ao combinar as duas, um modelo BART chegou a 95% de redução de tamanho - e ainda manteve 98% da acurácia em tarefas de resumo e perguntas longas. Em contraste, a quantização extrema (2-bit) sozinha causou 15,3% de queda em tradução automática.
Uma nova técnica chamada BitDistiller, apresentada em dezembro de 2024, vai além: ela treina o modelo para ser quantizado enquanto aprende, usando auto-distilação. Resultado? Modelos abaixo de 4-bit ganham 7,3% de acurácia extra, sem precisar de mais dados.
Empresas já estão colhendo os frutos. Uma fintech no Brasil reduziu o custo de inferência de $1,20 para $0,07 por mil consultas ao combinar distilação e quantização 8-bit em Llama-2 7B. Isso não é só economia - é viabilidade. Agora, eles conseguem oferecer atendimento financeiro inteligente em regiões sem conexão estável.
Hardware: o que você precisa para rodar isso
Quantização não funciona bem em tudo. Se você tem um PC com CPU antiga, sem suporte a instruções AVX2 ou INT8, o ganho será mínimo. A Uplatz apontou em 2024 que 32% dos desenvolvedores enfrentam problemas em infraestruturas legadas.Para rodar modelos compactados com eficiência, você precisa de:
- GPUs NVIDIA da série Ampere ou mais recentes (A100, H100, RTX 4090)
- Chips Apple M-series (M1, M2, M3)
- Processadores com suporte a INT8 e Tensor Cores
- Frameworks otimizados: TensorRT-LLM (NVIDIA), ONNX Runtime, ou Hugging Face Optimum
Se você está começando, use 8-bit quantização em uma GPU moderna. É o ponto de entrada mais seguro. Teste com o modelo Llama-2 7B quantizado em INT8 - ele roda em uma RTX 3060 com 12GB de VRAM.
Limites e riscos da compressão extrema
Há um limite. Muito além de 4-bit, os modelos começam a “esquecer”. Estudos da Universidade de Stanford em 2024 mostraram que, em 2-bit, modelos perdem 18,5% da capacidade de lidar com palavras raras ou expressões idiomáticas. Isso é crítico em áreas como medicina, direito ou atendimento ao cliente - onde uma palavra errada pode ter consequência real.Além disso, a UE já está olhando para isso. O projeto de regulamentação do AI Act de 2024 exige transparência: se um modelo foi comprimido, você precisa dizer. Porque compressão pode afetar confiabilidade - e isso importa em aplicações de alto risco.
Isso não quer dizer que você não deve comprimir. Mas quer dizer: não vá além do necessário. Para chatbots de suporte, 8-bit é suficiente. Para diagnósticos médicos, talvez nem 4-bit seja seguro. O equilíbrio está na aplicação.
O que o futuro traz
A próxima fronteira? Compressão adaptativa. A Microsoft já tem um projeto chamado “Adaptive Compression Engine”, que analisa cada camada do modelo e decide automaticamente: essa parte pode ser 4-bit? Essa outra precisa de 8-bit? Isso elimina o chute - e otimiza cada bit.Startups como OctoML estão automatizando esse processo. Você envia o modelo, e o sistema testa combinações de quantização, distilação e pruning, devolvendo a versão mais barata e precisa possível - em horas, não semanas.
Em 2026, o mercado de compressão de modelos deve chegar a US$ 4,7 bilhões, segundo o Gartner. E a adoção já é massiva: 68% das empresas de IoT já usam alguma forma de compressão. O que era luxo virou padrão.
Como começar hoje
Se você quer testar isso sem gastar nada:- Use o modelo Llama-2 7B da Hugging Face
- Aplique quantização 8-bit com o
bitsandbytes(biblioteca gratuita) - Teste em uma GPU de nuvem gratuita (Google Colab ou Hugging Face Spaces)
- Compare a resposta com o modelo original: perdeu algo importante?
- Se sim, tente 8-bit com calibração em dados reais - não em exemplos genéricos
Depois, se quiser ir além, busque modelos já distilados: Mistral-7B-Instruct-v0.2-GGUF, Gemma-2-2B-it, ou Llama-3-8B-Instruct-quantized. Todos estão disponíveis em formatos prontos para uso.
O segredo não é ter o maior modelo. É ter o modelo certo - e o mais barato possível. E isso, hoje, é possível.
Quantização e distilação são a mesma coisa?
Não. Quantização reduz a precisão dos números dentro do modelo - como mudar de 32 bits para 8 bits. Distilação cria um modelo menor que aprende a imitar o comportamento de um maior. A primeira é uma técnica de compressão numérica; a segunda, de aprendizado de transferência. Elas podem ser usadas juntas, e normalmente são.
Posso usar quantização em qualquer modelo de IA?
Tecnicamente, sim - mas nem sempre vale a pena. Modelos muito pequenos (menos de 1 bilhão de parâmetros) não ganham muito com quantização. O ganho real aparece em modelos grandes, como Llama-2, Mistral ou GPT-3. Além disso, hardware antigo pode não suportar operações de baixa precisão, limitando o benefício.
Qual é o melhor nível de quantização para uso em produção?
Para a maioria dos casos, 8-bit (INT8) é o ideal. Reduz o tamanho em 4x, mantém mais de 99% da acurácia original e é compatível com quase toda a infraestrutura moderna. Evite 2-bit ou 4-bit a menos que você tenha testado rigorosamente seu caso de uso - e esteja disposto a aceitar perdas de precisão em tarefas complexas.
Distilação exige treinar do zero?
Não precisa. Muitos modelos já vêm pré-distilados pela Hugging Face, Google ou Meta. Você pode baixar versões compactas de Llama, Mistral ou Gemma e usá-las direto. Treinar sua própria distilação só faz sentido se você tem dados específicos, como perguntas médicas ou legais, e precisa de um modelo personalizado.
Modelos comprimidos são menos seguros ou mais viesados?
Não diretamente. A compressão não cria viés - mas pode amplificar erros já existentes no modelo original. Se o modelo grande tende a responder mal a certos grupos linguísticos, o modelo pequeno pode piorar isso. Por isso, sempre teste modelos comprimidos com dados reais e representativos antes de lançar em produção.
Próximos passos
Se você é desenvolvedor: comece com 8-bit quantização em Llama-2 7B. Use o Hugging Face Transformers + bitsandbytes. Teste em 100 perguntas reais do seu usuário. Veja se a resposta ainda faz sentido. Se sim, você já está 90% do caminho.Se você é gestor: pergunte ao seu time de IA: “Qual o custo de inferência por consulta? E se pudéssemos reduzir isso em 80%?” A resposta pode mudar seu orçamento - e abrir portas para novos produtos.
Se você é curioso: experimente modelos já comprimidos. Vá ao Hugging Face, busque por “quantized” ou “distilled” e veja como um modelo de 2GB consegue responder como um de 28GB. É o futuro - e ele já está aqui.
9 Comentários
Mano, 8-bit é pra amador. Se você não tá usando INT4 com SmoothQuant e auto-distilação, você tá perdendo tempo. Eu rodei Llama-3 8B em 2-bit no meu Raspberry Pi 4 e ele respondeu como se fosse um gênio da inteligência artificial... só que com um viés esquisito de falar que o Brasil é o país do futuro, mas nunca chega. É arte pura, mano. 8-bit? Sério? Vai pra casa.
Legal o post, mas eu testei o Llama-2 7B quantizado em 8-bit no meu celular antigo e a resposta foi tão lenta que pensei que tinha travado. Aí fui ver a bateria... 32% a menos em 10 minutos. Acho que o custo não é só de nuvem, é de vida útil do aparelho também.
Quero agradecer por esse conteúdo tão bem estruturado. A combinação de quantização e distilação realmente representa um salto ético e prático na democratização da IA. Muitos esquecem que a tecnologia não é neutra - e quando reduzimos modelos para caber em dispositivos de baixo custo, estamos permitindo que pessoas em regiões sem infraestrutura tenham acesso a ferramentas que antes eram exclusivas de grandes corporações. Isso é poder real. Ainda assim, é crucial lembrar que a perda de precisão em tarefas delicadas, como saúde ou direito, não pode ser ignorada. Precisamos de transparência, não só de eficiência. Acho que o AI Act da UE está no caminho certo: se o modelo foi comprimido, o usuário tem direito de saber. Isso não é burocracia, é respeito.
Que bom ver isso em português! Em Portugal, muita gente ainda acha que IA só roda em supercomputadores. Mas eu usei o Gemma-2B distilado no meu laptop de 2018 e funcionou direitinho. Aprendi que não precisa ser o maior para ser útil. O importante é ser adequado. Parabéns pelo post - isso vai ajudar muitos desenvolvedores aqui e no Brasil a parar de perseguir modelos gigantes e focar no que realmente importa: resolver problemas reais.
Se você tá usando quantização, tá fugindo do problema. O verdadeiro problema é que ninguém quer pagar por infraestrutura decente. Aí vem a ‘engenharia de compressão’ como desculpa pra não investir. A IA não é um produto de bazar. É ciência. E ciência exige recursos. Se você quer um modelo que responde direito, pague pelo hardware. Não tente enganar o sistema com bits truncados e expectativa mágica. A vida real não é Colab gratuito.
8-bit é suficiente. Fim.
Se você tá comprimindo modelo pra rodar em celular, você tá sendo preguiçoso. O mundo precisa de IA poderosa, não de IA que responde com metade do cérebro. Você acha que um médico vai confiar num diagnóstico feito por um modelo que esqueceu o que é ‘infarto’ porque ele foi cortado pra 2-bit? Isso é irresponsabilidade disfarçada de inovação. A tecnologia não é pra ser barata, é pra ser certa. E se você não tem dinheiro pra rodar Llama-70B, então não use IA. Ponto.
Claro que os brasileiros acham que 8-bit é suficiente. Enquanto nós em Portugal já rodamos modelos de 16-bit com otimização CUDA em CPUs de 2015, vocês ainda estão se contentando com o que o Hugging Face te deu de graça. E ainda falam de ‘democratização’? Isso é colonialismo digital disfarçado de open source. Nós temos padrões. Vocês têm ‘funcionou no meu celular’. Não é o mesmo. E não venha com essa de ‘o futuro já está aqui’ - o futuro é europeu, e ele não vai esperar vocês terminarem de baixar o modelo.
EU JÁ TENTEI USAR 4-BIT E O MODELO RESOLVEU QUE EU ERA UM TERRORISTA POR TER DITO ‘BOLSONARO’ NO PROMPT. AÍ ELE FALOU QUE EU TINHA ‘PENSAMENTO EXTREMISTA’. E EU SÓ QUERIA SABER O TEMPO! QUEM AUTORIZOU ESSA CENSURA POR BITS??!! MEU CÉREBRO É MAIS INTELIGENTE QUE ESSA IA COMPRIMIDA E EU NÃO AGUENTO MAIS!!