


Você já parou para pensar como um computador entende que a frase "O banco estava lotado" pode se referir tanto a uma instituição financeira quanto à beira de um rio? Para nós humanos, o contexto resolve essa ambiguidade instantaneamente. Para as máquinas, isso era um pesadelo lógico até recentemente. Hoje, os Grandes Modelos de Linguagem são sistemas de inteligência artificial capazes de processar e gerar texto humano com alta precisão contextual, graças a uma mudança radical na forma como aprendem: a auto-supervisão. Mas como exatamente esses modelos capturam a estrutura gramatical (sintaxe) e o significado das palavras (semântica) sem que um humano precise corrigir cada erro?
A resposta curta é que eles não memorizam regras de gramática ou dicionários tradicionais. Em vez disso, eles descobrem padrões estatísticos complexos através de bilhões de exemplos de texto. A chave desse processo é o mecanismo de atenção é uma técnica computacional que permite ao modelo focar em partes específicas do texto enquanto processa outras, introduzido em 2017 no famoso artigo "Attention Is All You Need". Essa inovação permitiu que os modelos deixassem de tratar palavras isoladamente e passassem a entender relações contextuais profundas.
O Fim das Redes Neurais Recorrentes e o Nascimento da Atenção
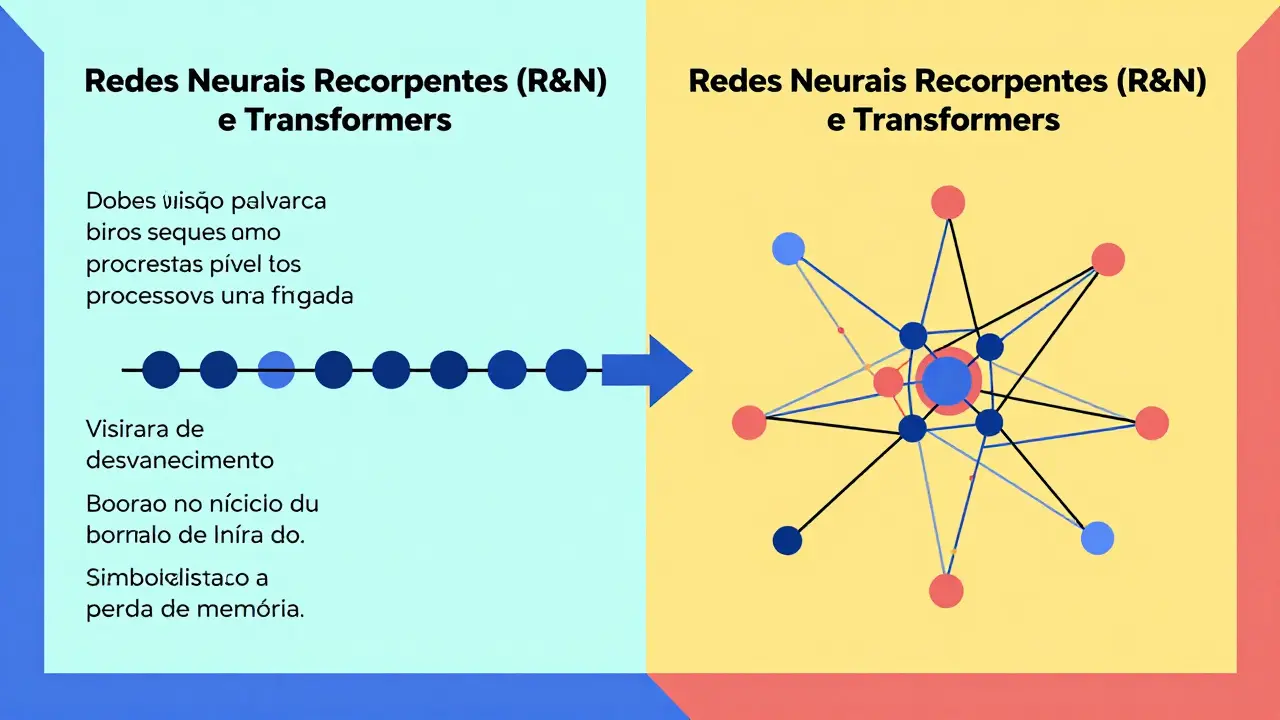
Antes de 2017, o padrão da indústria eram as Redes Neurais Recorrentes são arquitecturas de redes neurais projetadas para processar sequências de dados temporais. Elas processavam uma palavra de cada vez, tentando lembrar do início da frase até chegar ao final. O problema? Quanto mais longa a frase, mais o modelo "esquecia" o começo. Era como tentar decorar um telefone digitando-o letra por letra sem anotar nada.
O Transformador é uma arquitetura de rede neural baseada inteiramente em mecanismos de atenção, eliminando a necessidade de processamento sequencial recorrente mudou tudo. Ele lê a frase inteira de uma vez. Isso parece simples, mas gera outro desafio: como saber qual palavra importa mais para outra? É aqui que entra a magia matemática da atenção.
Como Funciona a Auto-Atenção: Consultas, Chaves e Valores
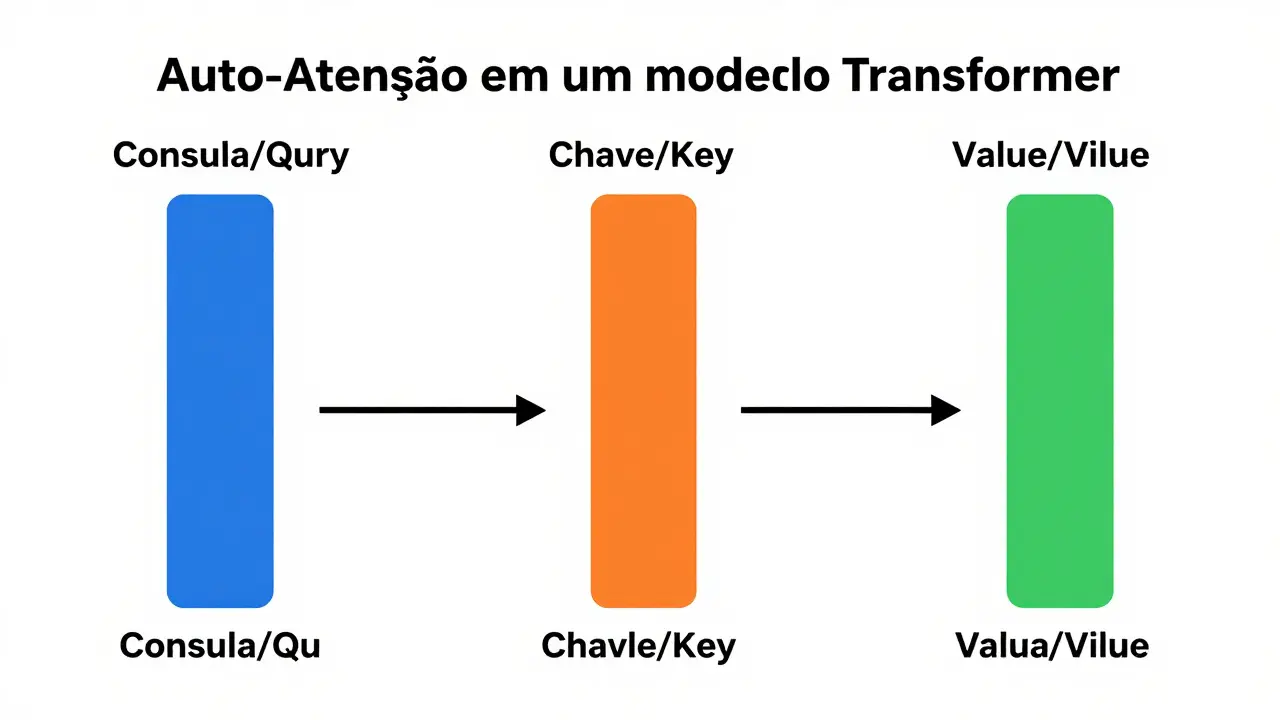
Dentro do cérebro digital desses modelos, cada palavra é convertida em vetores numéricos. Para entender o contexto, o modelo cria três tipos de vetores para cada token:
- Vetores de Consulta (Query): Pense nisso como uma lanterna. O modelo ilumina uma palavra específica e pergunta: "O que é relevante para mim neste momento?".
- Vetores de Chave (Key): São como etiquetas ou rótulos em todos os outros livros da estante. O modelo compara sua "lanterna" com todas as etiquetas para ver quais combinam.
- Vetores de Valor (Value): É o conteúdo real do livro. Uma vez que a consulta encontra as chaves relevantes, ela pega os valores correspondentes para formar uma compreensão completa.
Matematicamente, isso acontece através de um produto ponto escalonado entre consultas e chaves. O resultado é uma pontuação de atenção. Se a palavra "banco" estiver próxima de "rio", a pontuação de atenção para "água" será alta. Se estiver perto de "dinheiro", a pontuação para "transferência" sobe. O modelo soma esses valores ponderados, criando uma representação dinâmica que muda dependendo do contexto imediato.
Sintaxe vs. Semântica: Eles Estão Separados?
Muitas pessoas assumem que a IA separa a gramática do significado. Pesquisas recentes sobre cabeças de atenção especializadas em modelos como BERT é um modelo de linguagem bidirecional desenvolvido pelo Google para pré-treinar representações de texto, GPT-2 é um modelo generativo de linguagem criado pela OpenAI conhecido por sua capacidade de gerar texto coerente e Llama 2 é um grande modelo de linguagem de código aberto desenvolvido pela Meta mostram algo fascinante: a informação sintática é permeável à semântica.
Em outras palavras, mesmo as partes do modelo responsáveis por identificar sujeito e verbo (sintaxe) são influenciadas pelo sentido das palavras (semântica). Se você colocar uma combinação semanticamente absurda, como "A pedra pensou profundamente", a atenção dedicada às dependências sintáticas diminui. O modelo "percebe" que a estrutura está correta, mas o conteúdo não faz sentido, e ajusta seu foco. Isso espelha incrivelmente a maneira como o cérebro humano integra forma e significado simultaneamente.
| Característica | NLP Tradicional (RNN/LSTM) | Modelos Baseados em Atenção (Transformers) |
|---|---|---|
| Processamento | Sequencial (palavra por palavra) | Paralelo (frase/documento inteiro) |
| Dependências de Longo Alcance | Difíceis de capturar (decaimento de memória) | Fáceis de capturar (acesso direto a qualquer posição) |
| Contexto Dinâmico | Limitado ao histórico recente | Global e adaptável a cada token |
| Escalabilidade | Lenta para treinar devido à serialização | Alta eficiência computacional paralela |
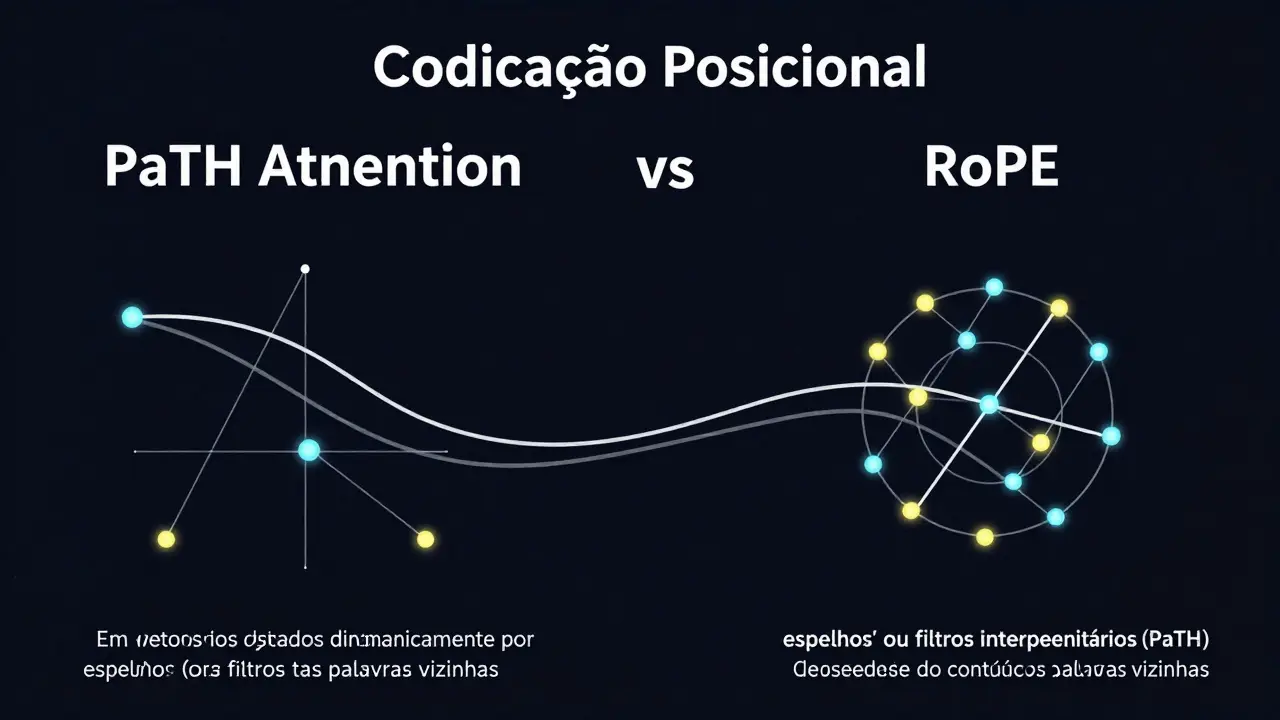
O Desafio da Ordem: Codificação Posicional
Há um detalhe crucial: a matemática da atenção pura não sabe a ordem das palavras. Para ela, "O gato sentou na caixa" é a mesma bagunça de números que "A caixa estava no gato". Como resolver isso?
Originalmente, usávamos Incorporações Posicionais são vetores adicionados aos embeddings de tokens para informar ao modelo a posição relativa ou absoluta de cada palavra na sequência. Um método comum era o RoPE é Rotary Position Embedding, uma técnica que aplica rotações baseadas na posição para codificar informações de ordem, que gira os vetores de palavras com base na distância fixa entre elas. Funcionava bem, mas tinha limites em textos muito longos.
Pesquisadores do MIT e IBM desenvolveram recentemente o PaTH Attention é um mecanismo de atenção avançado que trata as posições intermediárias como caminhos dependentes dos dados. Diferente do RoPE, que usa rotações fixas, o PaTH vê as palavras intermediárias como pequenos espelhos (reflexões de Householder) que ajustam a informação dependendo do conteúdo. Testes mostraram que modelos treinados com PaTH conseguem seguir comandos de escrita recentes mesmo após milhares de passos distrativos, superando métodos tradicionais em tarefas de raciocínio e memória de longo prazo.
Auto-supervisão: Aprendendo Sem Professores
Tudo isso funciona porque os modelos são treinados com Auto-supervisão é uma abordagem de aprendizado de máquina onde o modelo gera seus próprios rótulos de treinamento a partir dos dados brutos. Não há um humano dizendo "esta frase está certa". O modelo recebe um texto gigante e tenta prever a próxima palavra, ou preencher uma lacuna no meio da frase (máscara).
Para acertar a próxima palavra, ele precisa entender a sintaxe (para concordância verbal) e a semântica (para coerência lógica). Se ele erra, a função de perda matemática penaliza o erro, e os pesos da rede neural são ajustados. Após trilhões de tentativas, o modelo internaliza as regras implícitas da língua. É por isso que um modelo menor pode, às vezes, performar pior em rotulação de papéis semânticos não por falta de tamanho, mas por diferenças na arquitetura e na formulação dos prompts durante o treinamento.
Esquecer para Lembrar: O Futuro da Atenção
À medida que os contextos ficam maiores (janelas de 100 mil tokens ou mais), manter toda a atenção ativa torna-se caro e ruidoso. Humanos esquecem detalhes irrelevantes para focar no essencial. Novas abordagens como o sistema combinado PaTH-FoX é uma integração de atenção PaTH com Forgetting Transformer, permitindo que o modelo esqueça seletivamente informações menos relevantes permitem que a IA "esqueça" dados antigos de forma dependente dos dados. Isso melhora a estabilidade e o desempenho em benchmarks de entendimento de longo contexto, aproximando a eficiência computacional da cognição humana.
O que é auto-supervisão em modelos de linguagem?
Auto-supervisão é um método de treinamento onde o modelo aprende a partir de dados não rotulados, gerando seus próprios objetivos de previsão, como adivinhar a próxima palavra em uma frase. Isso elimina a necessidade de anotação manual massiva.
Como a atenção captura a sintaxe?
Cabeças de atenção especializadas identificam padrões estruturais, como a relação entre sujeito e verbo ou preposição e objeto. Embora essas conexões sejam muitas vezes baseadas em distâncias fixas de tokens, elas são moduladas pelo contexto semântico.
Qual a diferença entre RoPE e PaTH Attention?
RoPE usa rotações matemáticas fixas baseadas na posição absoluta. PaTH Attention usa transformações dependentes dos dados, tratando palavras intermediárias como filtros dinâmicos, o que melhora o rastreamento de informação em sequências muito longas.
Os LLMs realmente entendem o significado das palavras?
Eles capturam representações semânticas densas. Pesquisas mostram que a plausibilidade semântica afeta diretamente as conexões sintáticas, sugerindo uma integração profunda de significado e estrutura, similar à compreensão humana, embora baseada em estatística.
Por que o tamanho do modelo não garante melhor semântica?
Embora modelos maiores tenham mais capacidade, a eficácia na captura de semântica depende também da arquitetura, da qualidade dos dados de treinamento e de como as instruções (prompts) são formuladas durante o ajuste fino.